7.0
Cerb (7.0) is a feature upgrade released on May 26, 2015. It contains over 110 new features and improvements from community feedback. There are 87 additional improvements provided in 7 maintenance updates.
To check if you qualify for this release as a free update, view Setup » Configure » License. If your software updates expire on or after May 26, 2015 then you can upgrade without renewing your license.
Introduction
We design major functionality updates with backwards compatibility in mind – both technically and conceptually. This means that when you update between two versions in the same "generation" (e.g. 6.8 to 6.9), you can expect your environment to still meet the same system requirements, and your workers should still feel completely familiar with how the interface and common functionality works.
Every two years or so, we plan and release a "generational" update. Those are the milestone where we allow ourselves to break backwards compatibility. We remove features and concepts that have been deprecated by new improvements along the way, and we introduce new features and concepts based on thousands of ongoing discussions with the community and several more years of accumulated experience. Generational updates may be a bit more disruptive than typical updates, but they are where Cerb takes big leaps forward.
Each generation of Cerb has had a central theme:
In 4.x, the theme was a clean slate. We completely rewrote Cerb from scratch to use modern design principles, to be highly stable and secure, to enable a much faster pace of development, and to be extensible through plugins with our Devblocks framework.
In 5.x, the theme was automation. We introduced Virtual Attendants for automating common workflows in a very flexible way. That evolved into one of the main reasons people use Cerb at all, and it expanded the kind of problems Cerb is suited to solve.
In 6.x, the theme was productivity. We introduced fully customizable, shared workspaces and dashboards for delivering the perfect interface to each worker based on their needs. We refined how common actions were performed in the interface, and incrementally reorganized to reduce clicks and keystrokes.
For 7.x, the theme is personalization and machine learning. As Cerb has matured, we've seen a sharp increase in the seat count of enterprise deployments. While shared workspaces are great for keeping large teams on the same page, the common issue that nearly all of those busy environments run into is that workers end up looking at the same exact lists and tripping over each other while trying to find work. With judicious filtering and dispatching, those issues can be minimized – but the next issue becomes ensuring that workers are handling work in the appropriate order. Oftentimes, especially if a backlog forms, only the most recent records receive attention because workers approach their worklists like a traditional email client, which displays new messages at the top of the list. The older records become even later.
After a lot of research and experimentation, we've come up with what we feel is a powerful, flexible, and simple solution to this common problem:
-
Group members now have a variable level of responsibility for each bucket within the group. One worker may have a higher responsibility for clearing the group's inbox, while another focuses on a specialized bucket. Less actionable buckets like 'Spam' and 'Newsletters' can be pushed to the bottom of the list so they don't waste people's time.
-
Records within buckets have a variable level of importance (based on service level commitments, escalations, age, etc). A Virtual Attendant can simply boost the importance of new tickets from organizations with a service level agreement, and/or increase importance over time as unresolved tickets age. As you would expect from Cerb, you're not limited to these choices, and you can build whatever workflow works best for you.
-
Workers can sort worklists by their responsibility to see a highly personalized list: the records in their highest responsibility buckets, that are also the most important, and the oldest (all as a single sorted column). As a consequence, two workers may see the same set of records on a shared list, but in an entirely different order. Each of their top few records in the list are likely to be different and more suited to their strengths and duties; and rather than colliding with each other, or digging farther down the list for something more appropriate, they can get right to work from the first click.
-
Responsibility and importance information can be combined with metrics like availability (from calendars), qualification (from skills), and workload (assignments) to automatically recommend the most appropriate workers for a given record. Additionally, workers who already know the best person to handle an issue can simply nominate them.
-
When viewing worklists, workers are also given visual cues as to which records they have been recommended for. So even when two workers do indeed see the exact same records in the same order on a list, they can still click into the records that were recommended to them first, which are very likely to differ. As well, when a record requires multiple follow-ups to resolve, each time the conversation is revived, a worker who was previous recommended can handle it first. This saves new workers from wasting their time getting up to speed on the history of an issue when one of the original participants is still available. How do you know if an original participant is available? With one click, Cerb can now show you the current status, near-future availability, workload, and responsibility of those workers. In a few seconds, a worker can make a fully informed decision if a record is likely to be suitably handled by someone else, or if it needs to be nudged in a different direction.
Those changes are simple to explain, but together they provide our most efficient workflow yet, and considerably reduce collisions between workers as they find the best way to contribute.
Additionally, there are still many areas where Cerb can save even more time for workers. While observing worker actions, Virtual Attendants can learn to categorize new work, make recommendations about the best worker for each task, qualify leads with personalized follow-up questions, help troubleshoot common issues without worker intervention, suggest possible solutions to workers, etc.
Even after 13 years, it still feels like we're at the very beginning of a shift toward empowering and entrusting users with full control of the software they run. We appreciate your support for the idea that complex problems can be solved by giving people tools instead of features, openly sharing knowledge, encouraging creativity, and collaboratively iterating toward something better. Your contributions of feedback, referrals, and license renewals have helped Cerb grow into what it is today. There are billion dollar companies selling software that does a fraction of what we've all built.
- Jeff Standen, Software Architect, Cerb
Important Release Notes
-
Always make a backup before upgrading.
-
To upgrade your installation, follow these instructions.
Git repository URL change
We've renamed our GitHub repository so it no longer contains version names (e.g. cerb5, cerb6). GitHub automatically redirects requests from the old URL to the new one, but it's a good idea to still update your remote URLs to the new location.
First, check where your remotes are pointing now:
git remote -vIf you see wgm/cerb6.git in the URLs (instead of wgm/cerb.git), then you should run the following command:
git remote set-url origin https://github.com/wgm/cerb.gitNote: If your remote is named something other than ''origin'', then you should use the appropriate name in the command above instead.
After you run the ''set-url'' command, you can verify the change with the first command again and you should be all set.
Configuration file changes
These changes may cause a conflict to your framework.config.php file when upgrading from 6.9 to 7.0. Before upgrading, we recommend that you make a copy of your existing configuration file (or simply rename it). That file can be used, unmodified, with the 7.0 release. After upgrading, you can either copy the database details from the old configuration file to the new one, or you can just replace the new configuration file with the old one.
-
Defaulted
DB_CHARSET_CODEto 'utf8' in theframework.config.phpfile. If you're still using legacy 'latin1' encoding, now is a good time to convert your database to UTF-8 to properly handle multibyte languages. You can also just fix the inevitable conflicted line in this file after upgrading if you want to continue using your original settings. This new default was selected because it will match how most people are configured while causing a conflict for the least amount of people (i.e., not changing superior 'utf8' back to inferior 'latin1' on existing installs during the upgrade). -
The language encoding in the framework.config.php now defaults to UTF-8. Previously, this defaulted to ISO-8859-1 (Western Latin) if the database wasn't originally created with UTF-8 default encoding (as MySQL's default was 'latin1'). Using UTF-8 has been our recommendation for many years. UTF-8 can be used to display the web pages even if the database continues to use latin1.
-
Removed the deprecated cache settings in the framework.config.php file since caching is now configured from Setup->Configure->Cache in the UI. You should delete these lines entirely.
-
Removed the deprecated APP_DB_DRIVER setting in the framework.config.php file since 'mysqli' is now required. You should delete this line.
-
Added APP_DB_READER_* settings to the framework.config.php file. You can ignore these lines until you decide to set up writer-replica database replication.
Changes
- Responsibilities
- Recommendations
- Groups
- Workspaces
- Notifications
- Mail Transports
- Skills and Skillsets
- Usability and Aesthetics
- Scaling and Performance
- Security
- Development
- Plugin Development
Responsibilities
Bucket responsibilities can be configured for each group member
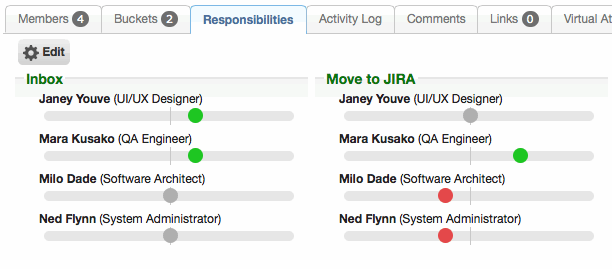
Group managers can now configure per-bucket responsibilities for group members. Responsibilities are displayed as a "delta" slider. By default, members have neutral responsibility for every bucket (the midpoint of the slider). By increasing or decreasing these responsibilities, actionable records (e.g. tickets, tasks) can be assigned, prioritized, and escalated to the appropriate members much more easily. Previously, all group members were considered to be fully and equally responsible for every bucket within the group.
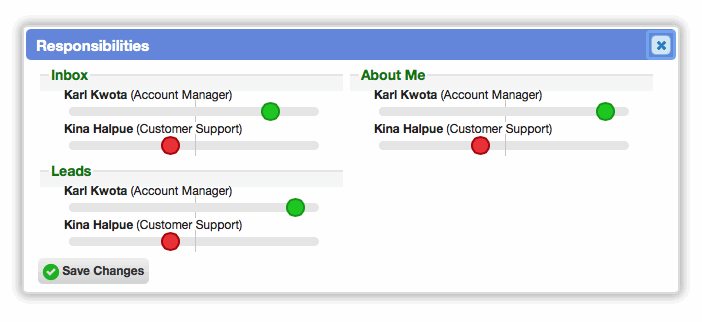
The 'is assignable' property has been removed from bucket records, as that behavior is now handled more robustly by group responsibilities. Previously, an entire bucket was marked as containing assignable work or not. Now, each group member can be explicitly assigned responsibilities for the various buckets. Buckets with no assignees are assumed to contain non-assignable work (for the purposes of recommendations, escalation, etc).
Worklists can be sorted by responsibility
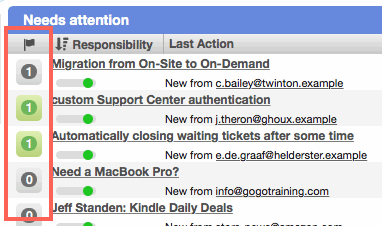
Ticket worklists can now include a 'Responsibility' column. This automatically filters the worklist to only records in buckets that the current worker is responsible for. When sorted, it considers responsibilities, importance, and record age (in descending order it's highest responsibility + highest importance + oldest).
This is the simplest way to provide personalized worklists to every team member and reduce the incidence of multiple workers attempting to work on the same record. It's our recommended workflow for discovering new work – although, in true Cerb fashion, you are not forced to use it. You can hide the Responsibility column and continue to sort your worklists by any field you like.
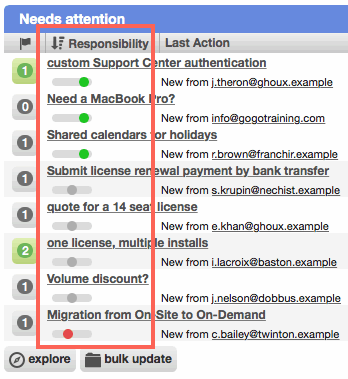
The order of the records in the worklist can be modified by changing the worker's bucket responsibilities, or the importance of individual tickets. Previously, tickets were often sorted in recently updated order, which inefficiently showed every worker the same exact list (and it made tickets move to the top of the list when they were edited for any reason).
Another great benefit is that workers who are only partially involved with handling tickets (e.g. developers, upper tier support) can just work until they clear their worklists of "green" (high) responsibility tickets. After that, the "gray" (neutral) and "red" (low) responsibility tickets can be left for other workers. This maximizes the impact of those workers without wasting their time having to hunt for the right places to contribute. A quick refresh of the worklist will show any new "green" responsibilities at the top of the list, without having to delve any deeper.
Service level agreement (SLA) functionality integrates with this approach very easily. You can have a worker or Virtual Attendant increment the importance of new tickets from specific contacts. The workers most responsible for those buckets (e.g. Sales, Support, Development) will be shown those higher importance tickets first (and among those, the least recently updated).
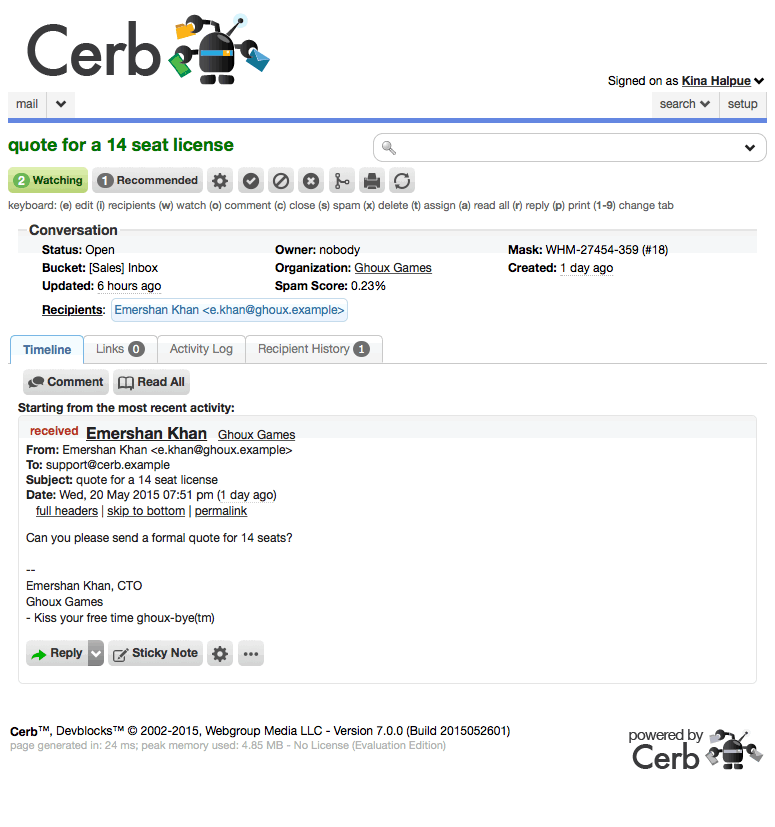
Recommendations
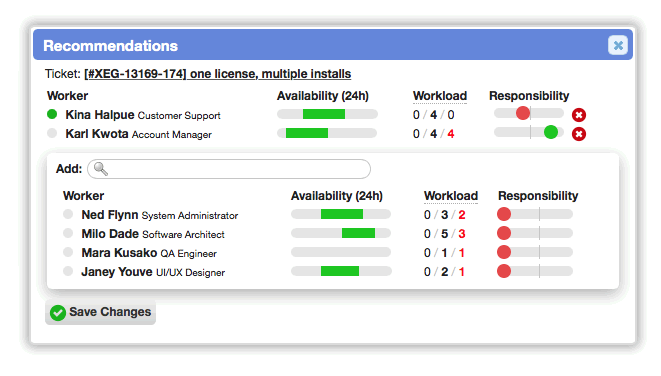
Recommend workers for actionable records
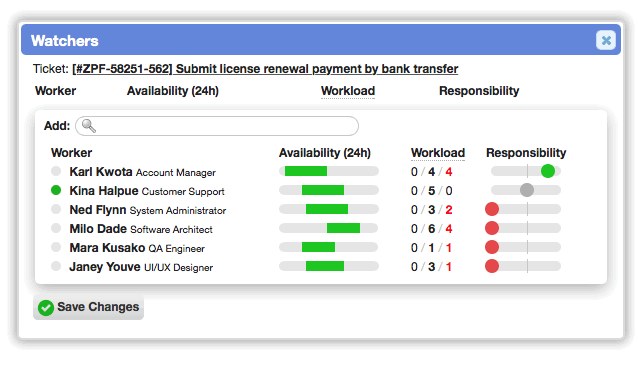
A recommendation system has been implemented to assist human and Virtual Attendant dispatchers in assigning and escalating work. For instance, in ticket worklists, currently recommended workers are displayed along with the ability to make new recommendations. Next to each worker is a summary of their current status (online/offline), their next 24 hours of availability, their current workload (assignments, recommendations, and unread notifications), and their responsibility for the currently selected bucket.
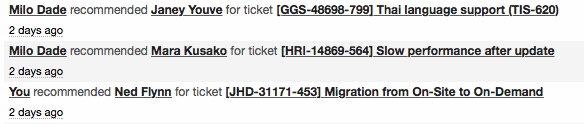
In environments with many interchangeable workers on different schedules, recommendations are strongly encouraged compared to changing the owner of a record. In previous versions, when a record was assigned to a worker, it could disappear for everyone else. This could give the illusion of an issue being handled even if that assigned worker was unavailable. With the new system, several workers can be recommended at once, and the first to accept the work can assign themselves as the owner. The notifications for the other recommendations can be cleared (even if unread) so those workers aren't bothered to look at a record that is already being handled.
With recommendations, a worker can unassign themselves after responding so that the record is available for anyone else to handle (e.g. end of shift, vacation, etc). When workers leave themselves as a recommendation while unassigning, they will be given first priority based on their past involvement if those records need attention again in the future. Without recommendations, a different worker may be assigned for each subsequent reply, even if the original responder was currently available, which is very inefficient (as each new worker has to redundantly get up to speed with the issue before contributing).
When there are multiple recommendations on a record, the recommender system considers the bucket responsibilities, availability, and workload of each recommended worker. This makes it easy to craft Virtual Attendant behaviors that use these metrics when selecting the best assignee.
Currently, bucket responsibility is the primary metric used for recommendations. In near-future 7.x updates, recommendations can be expanded to utilize many more metrics (e.g. importance, availability, skill qualification, approachability, past involvement, lateness, etc). Most of the work is already done to collect and use these metrics, but we want to gather usage feedback based on the simpler responsibility-based implementation before making things more complicated. During development, we also had experimented with the recommender system as a learning neural network (i.e. supervised machine learning), and that's likely to be something we'll revisit in a future update.
See current recommendations on worklists
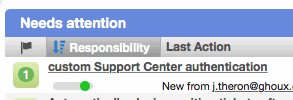
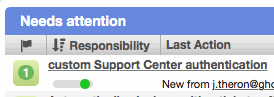
On actionable worklists (e.g. tickets), a new "Recommendations" column is displayed where the Watchers column appeared in earlier versions. For each row, a count is displayed on a button for the number of people recommended to work on that record. If the current worker has been recommended, the button will be colored green to draw their attention to it. Clicking the button displays a detailed overview of the current recommended workers, as well as the ability to add or remove recommendations.
The new Recommendations column can be disabled on ticket worklists from the customize action.
Ticket worklists can be filtered to records that have been recommended to a specific worker, or to those that have not been recommended to any worker. This greatly simplifies dispatching workflows.
The new "Recommendations" button is also available when replying to a ticket.
Recommendations activity is logged and triggers notifications
Activity log entries and notifications are created when a worker is added or removed as a recommendation on a record.
Groups
Public and private groups
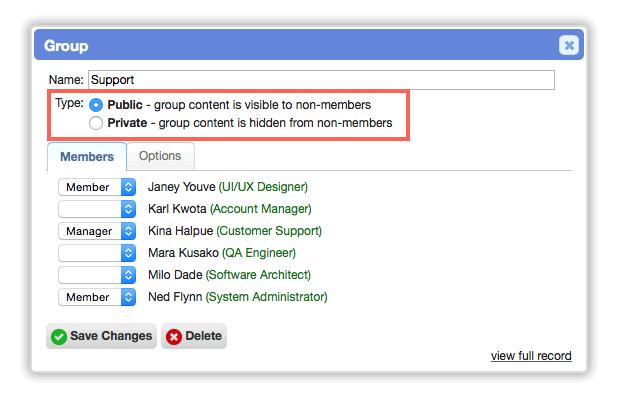
Groups can now be marked as 'public' or 'private'. The content (e.g. tickets/tasks) in a public group are visible to non-members. This is very useful if you want only a few workers to be responsible for a group like Support, Billing, or Development, but you want all workers to have access to them. Private groups hide their content from non-members. Previously, all groups were treated as if they were private; which confused member responsibilities.
Consolidated group configuration
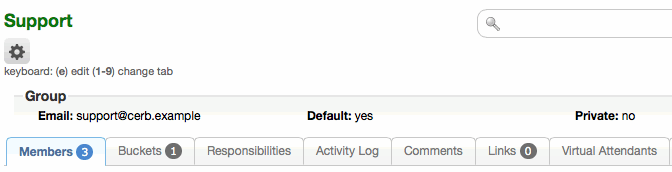
Previously, the management of groups was handled in three different places (Setup->Groups, the groups page, and group profiles). These areas have been merged for simplicity. New groups can be added from Setup, but they are now configured directly from the profile page. The 'groups' page (in the top right of the navigation menu) has been removed.
Inbox buckets are now actual records
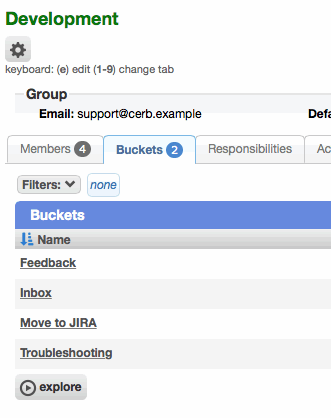
Group inbox buckets are now actual records in the database. Previously, inboxes were virtual records with id=0. This had simplified some early workflows since 4.0, but it also made several queries less efficient because the group had to be compared every time as well. For instance, filtering by a 'Sales' inbox would require filters like (group_id=3 and bucket_id=0) rather than just (bucket_id=5). The 7.0 update automatically creates an inbox bucket for each group and moves the appropriate tickets into it, and the configuration of Virtual Attendant behaviors, mail routing rules, and worklists will be automatically updated.
[CHD-2839] The group and bucket filters on ticket worklists are now independent. Previously, the group filter managed both of them. When clicking group and bucket subtotals from a worklist sidebar, only a single filter is added now. The bucket filter prefixes group names, like 'Sales: Inbox'. Filtering by inboxes now works as expected; where previously, adding a "not in" filter based on group inboxes excluded every group's inbox.
Worklists and profile pages for bucket records have been added.
Group buckets are now always listed in alphabetical order. Previously, buckets were manually ordered. This made it less intuitive to find a specific bucket in a list. Ticket worklist subtotals by bucket now sort properly by count.
Added a built-in importance field to ticket records
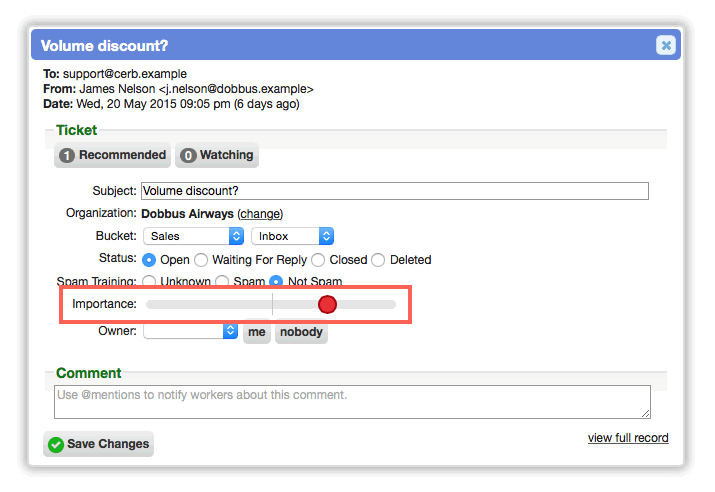
A new 'Importance' field is available on ticket records. Importance is set by dragging a slider when editing tickets, rather than dealing with arbitrary labels like 'low', 'normal', and 'critical'. The importance property is used as a metric in the new recommender system and when sorting responsibilities.
Previously, prioritization was often handled using custom fields, but that approach was inconsistent between Cerb environments. Additionally, using discrete priority categories made it more complicated to create escalation workflows, where the new importance field can simply be incremented or decremented by some amount in the range of 0 to 100. This means that Virtual Attendants can just add a fixed value to the importance of new tickets for organizations with a service-level agreement (SLA), or when tickets are left idle for a certain period of time.
The importance field defaults to 50/100 (the midpoint of the slider). This allows importance to be adjusted up or down upon initial record review. When sorting by importance, this also allows new tickets to be reviewed before anything that has been set to a lower priority (where, previously, everything on the low priority end was mixed together with new tickets).
When sorting by the Importance column, the list will also sub-sort each tier of importance with the oldest tickets first (i.e. most important and oldest first).
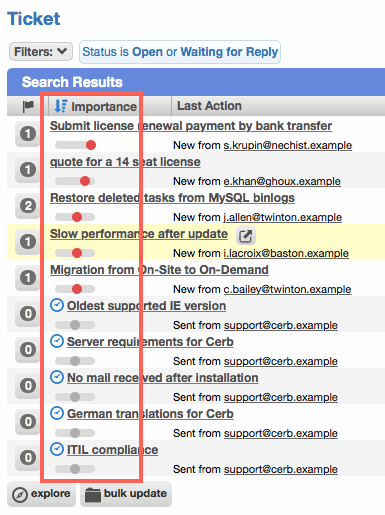
HTML messages are displayed directly in the conversation
When reading mail, HTML messages are now displayed right in the conversation without having to click the original_message.html attachment to view them.

A worker preference has been added for disabling the rendering of HTML messages and always showing the plaintext part instead. This can be found in the 'Mail' section from the 'Settings' page in the worker menu.
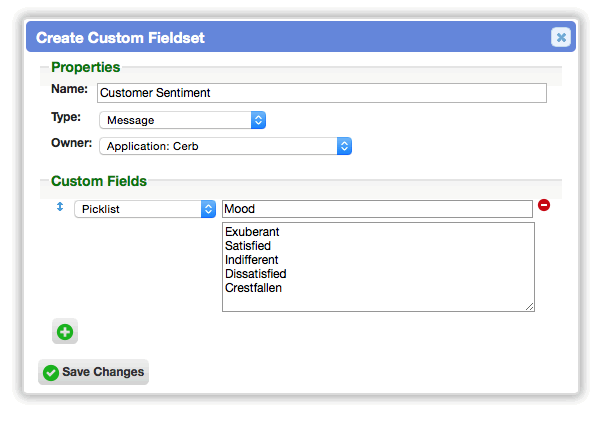
Custom fields and fieldsets can be set directly on message records
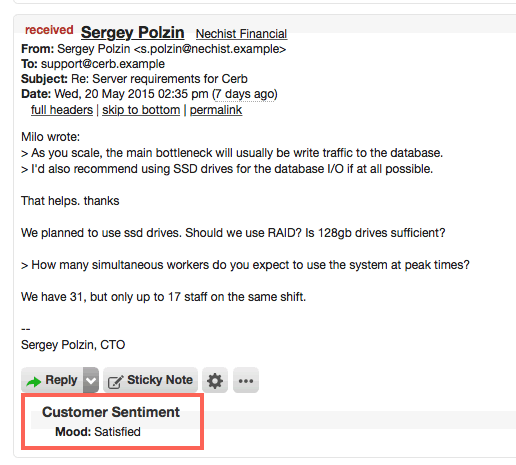
Custom fields and fieldsets may now be set directly on message records. These fields are displayed at the bottom of each message in a ticket conversation (in the same format as other record properties). This is very useful for storing per-message data like customer satisfaction surveys/ratings, sentiment tracking (satisfied/dissatisfied), etc.
Workspaces
Improved customization of worklists
[CHD-2422] When customizing a worklist, the process of selecting which columns to display has been drastically simplified. Previously, up to 15 dropdowns were displayed for selecting from the list of available columns. This was very cumbersome, and there was never a situation where adding the same column twice made sense. Now, all of the available columns are displayed as a list of checkboxes. Selected columns are displayed in order at the top. New columns can simply be checked and then dragged into the desired position. Additionally, this removed the arbitrary limit of 15 columns, and workers with wide screens can enable as many columns as they want.
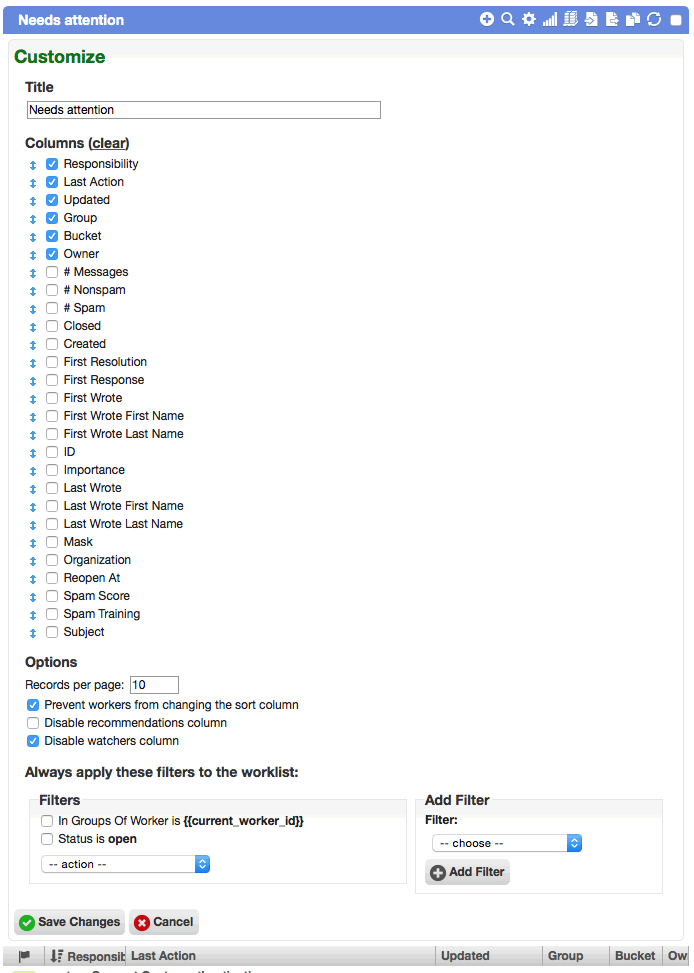
Worklists can now provide specialized options in the customize section. For instance, the watchers column could be hidden or sorting could be disabled. Many people have asked for the ability to display dates in different ways based on the worklist (e.g. absolute or relative timestamps), and this makes implementing those feature requests very simple going forward.

Custom worklists on workspaces can now be configured by the owner to prevent workers from changing the sorting on the list. This is particularly useful for ensuring a consistent team workflow (e.g. everyone is sorting by highest responsibilities + highest importance + oldest). Previously, the owner of a workspace could configure the default sorting but workers could always change it.
Notifications
Notifications are now directly based on activity log entries
Notifications are now more closely related to Activity Log entries. A notification message can link to multiple records (e.g. actor and target). This is also more readable since the entire notification isn't an underlined link. Previously, notifications were just a message and an arbitrary link, where the link could become stale if the record moved (e.g. Cerb install changed URLs/paths). Notifications are now based on the same events as the Activity Log. The upgrade process will automatically convert any existing notifications to the new format.
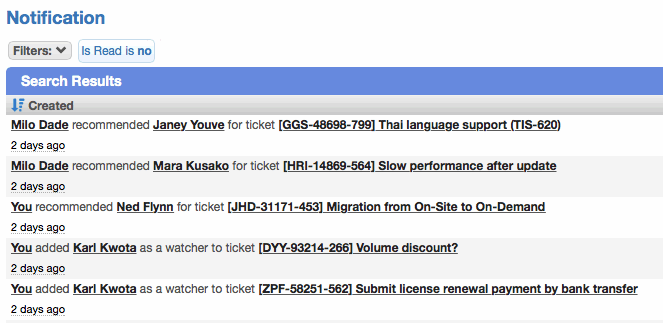
Notification worklists can be subtotaled by activity type
Notification worklists can now be subtotaled by activity type. This makes it much easier to clear out many notifications of the same type (e.g. "Worker followed a record").
Mail Transports
Multiple mail transports can be configured for delivering mail
[CHD-374] [CHD-4003] Multiple outgoing mail transports may now be configured from Setup->Mail->Transports (e.g. SMTP, Mailgun). Previously, it was only possible to have a single outgoing mail server configured for the entire Cerb installation. This change makes it easier to manage multiple brands in a single Cerb instance, where various sending domains need to use different SMTP servers or authentication methods. It's also possible to implement new transports through the plugin system to take advantage of special features like the Mailgun API (open/click tracking, campaigns, auto-unsubscribe links, etc). Each reply-to address (the addresses Cerb sends mail as) can now specify a particular mail transport to use. A default mail transport can be configured. The previously configured SMTP server will be automatically created as the new default during the upgrade process.
Null mail transport
Added a new 'Null' mail transport. This discards outgoing mail without delivering it, which is useful for development, testing, and evaluation environments where live mail should not be delivered. Previously, the same functionality was possible by configuring a null transport in a mail server like Postfix – or using a dummy mail server like the one provided by Python – but those options require several extra steps. Now Cerb can simply be configured to not deliver mail, and it can be installed on test machines without needing access to a live mail server during installation.
Skills and Skillsets
Implemented skills for matching workers with the most appropriate tickets, tasks, calls, opportunities, etc. Skills have the following levels: none, basic, intermediate, advanced, and expert. A worker with a higher level of skill than the requirement is considered to be 'overqualified', while a worker with a lower level of skill than the requirement is 'underqualified'. A worker with the exact same skill level as a requirement is the best fit. This also provides a much more sophisticated way to automatically assign records to workers.
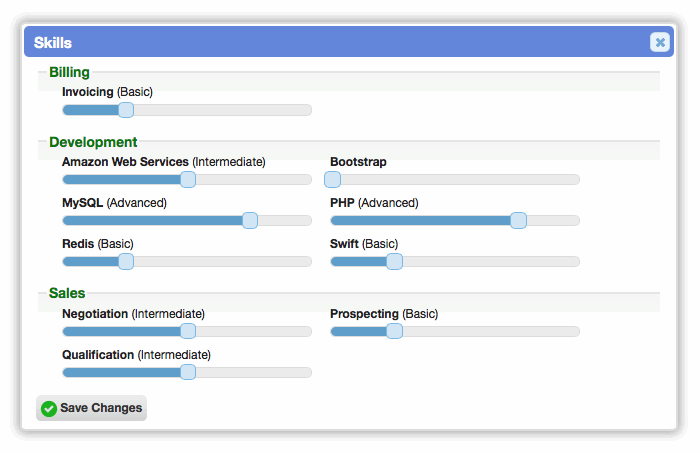
Added skillsets as a way to group related skills. For instance, a Development skillset may contain skills like 'PHP', 'jQuery', and 'MySQL', while a 'Sales' skillset would contain 'Prospecting', 'Qualification', and 'Negotiation'. It's much quicker to add a single skillset to a record than trying to find and add all the individual skills. Skills in a skillset are ranked by dragging a slider to the desired level of proficiency.
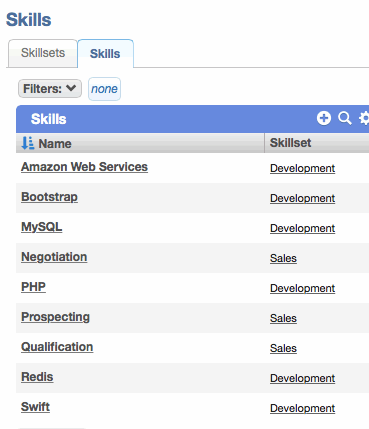
A 'Skills' tab is now displayed on worker profiles. The worker whose profile it is, or any admin, will see an 'Edit' button at the top of the tab to modify the skills and experience levels.
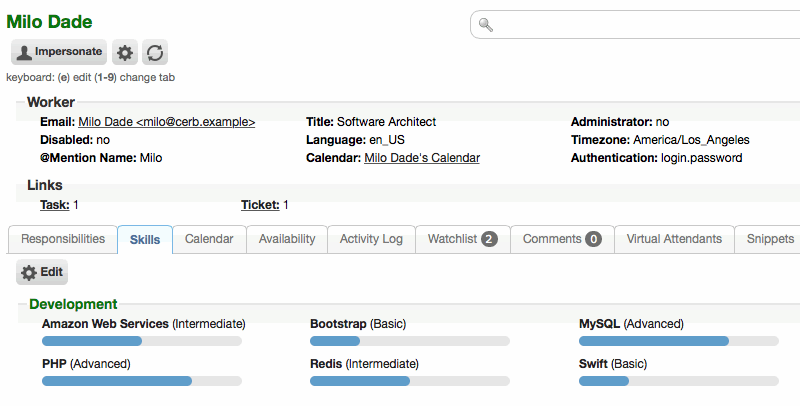
Skills will be utilized by upcoming features (e.g. improvements to the recommender service).
Usability and Aesthetics
User interface style improvements
The icon style of the user interface (UI) has been modernized. Previously, we used two different sets of sprite icons. These images had conflicting styles and distracting colors which led many people to comment that the UI looked "dated". The new icons are font-based (via Glyphicons), which allows them to display cleanly at any size, and to be colorized consistently using standard CSS. They are monochromatic in color and "flat" in style.
The style of buttons throughout the UI has been improved. Button icons are now black on gray, and the labels are bold. This makes buttons more pronounced and recognizable compared to normal content.

The style of worklists has been improved. The list icons in the top right of the blue bar are now white (rather than multicolored). The action buttons below the list are black on gray. The peek button (shown when hovering over a row) now uses a standard "new window" icon.

Activity log improvements
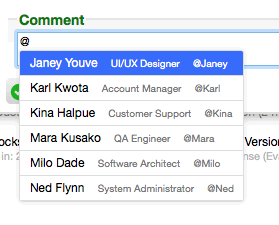
The Activity Log and Notifications are now more personalized with "you", "yourself", and "themselves" in place of actor names. For instance "You replied to this ticket", "You assigned yourself to this ticket", "Milo recommended you on this ticket", and "Kina recommended themselves on this ticket".
Installer improvements
-
The installer can now configure outgoing mail using the SMTP or Null transports. The latter makes it easier to set up development, testing, or evaluation environments where live mail isn't required or desirable.
-
When the installer creates the initial administrator account, the worker's first and last name can be provided so they don't need to change that after logging in.
-
When the installer creates the initial administrator account, the worker's timezone can be set. The initial value is automatically detected.
-
When the installer creates the initial administrator account, the worker's default calendar is now automatically created. Previously, this had to be created manually after logging in, while adding subsequent new worker accounts would automatically create those calendars.
-
Updated the aesthetics of the installer to reflect the newest Cerb style.
@mention improvements
[CHD-3995] When using @mentions to notify workers, the auto-suggestions now display each workers nickname, and filtering by that nickname (in addition to the full name) is now supported.
Improved watcher functionality on worklists
The usability of the Watchers column on all worklists has been improved. Previously, each row had a button that toggled watcher status for the current worker, and a menu provided the clunky means to add or remove watchers. Now, a button is displayed row each row with a count of the workers watching the record. If the current worker is watching the record, the button will be colored green as a visual cue. Clicking on the button now displays a detailed overview of the current watchers: status, availability, workload, and responsibility for the current bucket. This new behavior is also provided from watcher buttons on peek popups and profiles, enabling more informed decision-making.
The Watchers column can now be disabled on ticket worklists from the customize action. Previously, this was always displayed, even in environments where it didn't make sense (e.g. personal webmail).

Miscellaneous worklist improvements
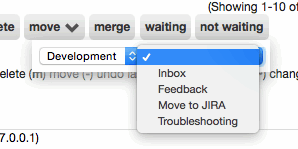
- [CHD-3580] The 'move' action on ticket worklists is now more efficient. Previously, this displayed a searchable menu with a long list of every group and bucket. Now it simply displays two linked dropdowns, with the first selecting a group, and the second selecting one of its buckets. This is more consistent with how groups and buckets are set in the rest of the app.
-
Implemented 'explore' mode for group and worker worklists.
-
Implemented 'explore' mode for worker worklists.
-
The 'Group' column on ticket worklists now provides links to each group's profile.
-
The 'Bucket' column on ticket worklists now provides links to each bucket's profile.
-
The 'Owner' column on ticket worklists now provides links to each worker's profile.
-
Implemented the ability for a single worklist column to sort by a composite of any number of underlying fields. For instance, on tickets, sorting by the 'responsibility' column can sort by responsibility and then by importance.
Profile improvements
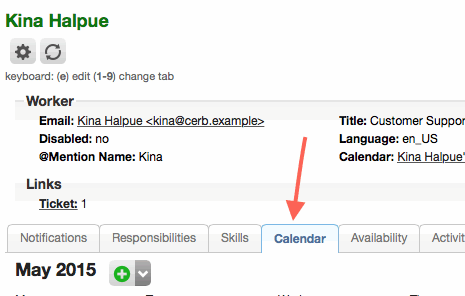
- Worker profiles now have a tab to display their primary calendar. Previously, profiles only displayed availability, and a link displayed the primary calendar on a separate page.
-
Added keyboard shortcuts to group profiles.
-
Added keyboard shortcuts to worker profiles.
Mailbox configuration improvements
- In Setup, changed the 'Mail->POP3 Accounts' menu option to 'Mail->Mailbox Accounts'. There can be multiple types of mailboxes (POP3, IMAP, and possibly even API-driven accounts), so naming the menu option as only one of these was a source of confusion.
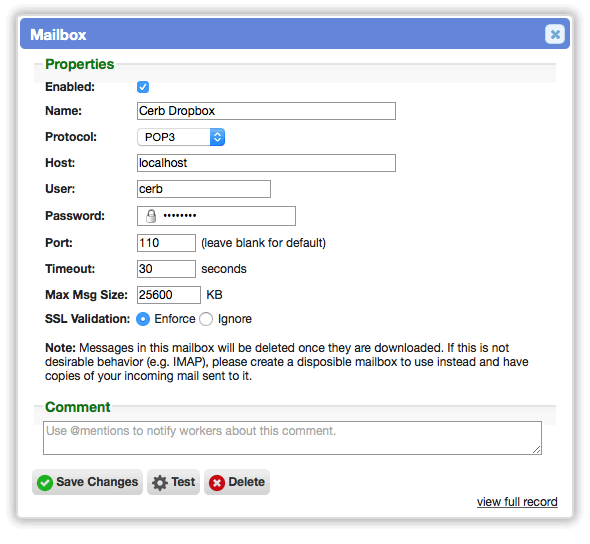
- Mailbox accounts are now first-class records with worklists, profiles, peek, etc.
Miscellaneous improvements
- When the Gravatar plugin is enabled, profile pictures for workers and contacts are now rendered as circles rather than squares. This provides a more modern look.
-
[CHD-3656] The Gravatar default icon is now served directly from Cerb. Previously, this was served from a static URL, which was triggering browser warnings for SSL connections. When the Cerb install is behind a firewall or on an intranet, the Gravatar plugin can now be configured to use any URL for the default icon.
-
Changed the default behavior of the mail reply textarea to not auto-grow as the user types new lines. This can be re-enabled from worker settings. There were numerous reports of it causing lag in some browsers, as well as causing some weirdness with scrollbar positions.
-
Fixed some usability issues with the snippets popup when composing and replying to mail. In some browsers (especially Internet Explorer) the focus of the reply textarea could be lost when inserting snippets. Additionally, when closing the snippets popup the reply textarea scrollbars could skip around and require manual repositioning.
-
Added a 'view full record' permalink to group peek popups.
Scaling and Performance
Support for writer/reader database connections
[CHD-1870] Cerb now fully supports writer/reader database replication setups, where writes are sent to the master(s) and reads can be distributed among many replicas. Writer/reader replication has always been possible for high-availability and failover, but Cerb never took advantage of the idle replica databases for improving read performance. Previously, writer/reader query splitting was only naively possible by using database proxies like MySQLproxy or MaxScale as an intermediary. Those tools simply sat between Cerb and the database and routed SELECT queries to the replicas and everything else to the master. That process couldn't handle some important types of queries that depend on deeper application knowledge (temporary tables, character encoding, etc). By handling the routing to master or replica connections directly in Cerb, we can make those decisions very intelligently while also optimizing performance.
Meta information about the database (e.g. table list, table schemas) is always read from the master to ensure that the most recent information is used. Similarly, all database queries executed by the installer and update process are sent to the master because "eventual consistency" (updates in replicas slightly lagging behind updates in the master) could cause inconsistencies. These processes run infrequently and don't have a major impact on performance or scaling. Temporary tables are created on the same connection where they're used (e.g. master for maintenance queries that modify the database, replicas for searches that join temporary tables created from external search services). All the rest of the read-intensive content – like workspaces, worklists, dashboards, reports, and profile pages – are almost exclusively sent to replicas. Utilizing database replicas to serve most of the content is where the major performance improvements and scalability come from.
The use of database replicas for improving read performance can be enabled by setting the APP_DB_READER_* values in the framework.config.php file (host, user, password). While a single replica host can be defined in Cerb, you can put a proxy or load balancer in front of multiple replicas to scale. This could rotate between the replicas for each new connection (e.g. round-robin, least loaded, most current). Similarly, master-master replication can be utilized by specifying a proxy or load balancer for the master host. Since Cerb often generates multiple parallel HTTP requests for a single page (the outer page, a tab's content, and several worklists or widgets), multiple database replicas can be utilized to render this output more quickly.
Cerb will always route queries to either a master or replica, but when replicas aren't configured then the master serves as both roles. In this case, a single connection will be used (instead of two) to minimize wasted resources on the database server.
The database storage engine will now use the default writer/reader connections when no external host is specified. The connections are also established lazily, so a replica read doesn't require that the master be contacted at all.
When Cerb caches all records for small sets (workers, roles, groups, buckets, custom fields) it will always use the master database. These caches are usually invalidated based on changes taking place in the database, and retrieving the latest record from the master ensures the most recent copy. Reading immediately from a replica could cache records prior to the change taking place if replication was slightly delayed.
Support for virtual filesystems
Virtualized the way filesystem paths work for storage and plugins. In most cases the previous way worked fine (where cerb/storage/ was the assumed path), but this change makes it possible to host multiple instances of Cerb in cloud environments where the individual storage paths aren't located at cerb/storage/. With a single site, that path could be symlinked to anywhere else; but when multiple sites share the same Cerb files, the solution needs to be at the application-level rather than in the underlying filesystem. This change makes it much easier to run and scale cloud deployments of Cerb using distributed filesystems, etc. The storage location can even change while Cerb is running and installed plugins won't be affected.
Database performance improvements
Improved the performance of several operations involving temporary tables (e.g. searching) by ensuring that primary keys were added to the temporary tables.
Removed extraneous checks for the database connection status during a single request. Database connections no longer open until they're first used, and this connection checking is now handled in a simpler way.
Prevented extraneous database query lookups when the ID of a record is zero (non-existent). These extra lookups were happening in places like ticket profiles, where organizations are looked up for senders, and the orgs may be blank.
Email address and organization records are now retrieved more efficiently with a local memory cache for the duration of the request.
Worklist performance improvements
Worklists now automatically persist worker changes (page, sort, columns, filters) and only update the database when necessary, once at the very end of the request. Previously, developers had to explicitly write a ::setView() call to persist changes. Persistence was also forced in some places in the API as well. This led to a situation where changes to a worklist could be persisted multiple times per request, even when there weren't any changes. This created extraneous write queries to the database server.
Session performance improvements
The worker activity information in "Who's Online" now only updates once per request. Previously, it was possible for multiple activities to be sequentially written to the database even though the last one would replace all the earlier ones. This created some extraneous write traffic on the database.
Previously, all worker activity for "Who's Online" was updated once per 30 seconds. This waiting period has now been extended to once per 60 seconds. When this interval was first established, there wasn't a way for some activities (e.g. viewing a ticket profile) to ignore the waiting period and always update a worker's activity. Now that this is possible, the default activity can wait longer to update in order to reduce database write traffic.
User interface performance improvements
When remembering the previously selected tab on a page, Cerb now efficiently stores this information in HTML5 localStorage in the worker's browser (client-side), rather than persisting it to the session (server-side). To the worker this behaves identically; but from a performance standpoint, this optimizes away a lot of needless session updates that wrote to the database (and possibly needed to replicate, and/or be backed up in the binary logs, etc).
Security
Removed RSS feed functionality on worklists
Removed the RSS feed feature on ticket, task, and notification worklists. This was inherently insecure as any worker could create a feed that disclosed information outside of Cerb if the URL was known. RSS feeds can be implemented in a more secure way using the Web-API or Virtual Attendant webhook behaviors.
Development
Added a unit testing framework
Added a unit testing framework (PHPUnit) and many new tests to the 'tests/' directory of the project. This can be used for automatically testing builds during clones, commits, pull requests, etc. Unit tests help to ensure that developers and contributors don't break existing code while implementing new features or fixing bugs. We have many testing scripts that will be consolidated here so they're accessible by the entire community. The tests are run from the command line and access to the directory should be blocked for all web traffic.
Added automated tests that create a new database, run all the patches, and add a default admin worker. This is used as the baseline for fully automated browser testing with Selenium.
Added automated browser-based functionality tests with Selenium
Added automated browser tests using Selenium to log in to a fresh installation, close the tour, add the default mail page, configure mail transports, reply-to, add a default role, add a group, create co-workers, import orgs and contacts with a CSV file, add an owner custom field to tasks, enable plugins, configure calendars, etc.
Plugin Development
Writer/reader database connections
To use the new read/write splitting to writer/reader databases, developers should update their plugins to use the new database functions. For instance, $db->Execute() has been deprecated in favor of ->ExecuteWriter() and ->ExecuteReader(). Existing calls to ->Execute() will always be sent to the master. Likewise, new writer/reader methods exist for ->GetOne(), ->GetRow(), and ->GetArray(). Existing calls to the generic, deprecated method will always be sent to read replicas. To optimize performance, these queries should be made explicitly as reads or writes so they can be routed accordingly.
CSS preprocessing with Sass
The cerb.css stylesheet is now built using the Sass CSS preprocessor. The source files are in the /install/extras/developers/css/cerb.css/ directory. This makes it much easier to manage the styles consistent for a large and complex application like Cerb.
Arbitrary activity log entries
Arbitrary activity log entries can be created using the 'custom.other' event point. This can be done from plugins or the REST API. In most cases, it's still ideal to explicitly define new events from a plugin. This allows them to be subtotaled, filtered, etc.
Neutral network service
Added a neural network service to Devblocks to support trainable, real-time machine learning in various features and for third-party plugins.