7.2
Cerb (7.2) is a feature upgrade released on August 5, 2016. It contains over 143 new features and improvements from community feedback. There are 85 additional improvements provided in 5 maintenance updates.
To check if you qualify for this release as a free update, view Setup » Configure » License. If your software updates expire on or after May 1, 2016 then you can upgrade without renewing your license.
Introduction
We aim to ship a major functionality update every 3-4 months. The development cycle for 7.2 was longer than usual (about 7 months), since it evolved in tandem with the introduction of Cerb Cloud.
We've spent several months auditing the daily usage of Cerb Cloud instances with 7.2 and fine-tuning our code and queries. We revamped our platform to take proper advantage of cloud-based deployments (e.g. load balancers, multiple web servers, databases with read replicas, distributed filesystems, distributed caches, Elasticsearch, etc). A single instance of Cerb is now capable of painlessly scaling to hundreds of concurrent workers who field tens of thousands of messages per day. There is nothing proprietary in how we're accomplishing that – even if you run Cerb on your own hardware, the "cloud" focus of the 7.2 release provides you with many major scaling and performance improvements.
Many other improvements in 7.2 are similarly focused on scalability: dashboard widgets load in parallel, bulk update on long worklists runs incrementally rather than taking forever without any progress output, fulltext searches that return too many results help the worker be more specific, the schema and database indexes were made more efficient by combining related fields and records, etc.
The other major focus of 7.2 was on improving the flexibility and usability of worklists and Virtual Attendant behaviors, since they are the basis of almost everything interesting about Cerb. As we've consulted with teams who are deploying Cerb, they've asked for seemingly simple things that Cerb just couldn't do easily: "How do I build a worklist with tickets I'm either the owner of OR a watcher of?", "How do I build a worklist with a non-continuous range of values, like < 5 OR > 10?", "How do I build a worklist of records with at least one watcher who is not myself (without explicitly filtering for every other worker on my 70 person team)?", etc.
To that end, quick search has been significantly improved. You can now include the same filter multiple times, use lists and negation, and (most importantly) you can group filters with AND and OR. This makes so many new workflows possible.
Similarly, when we run through a training session with a new team, there's a fairly universal pause as the huge list of 800+ placeholder options results in cognitive overload. Those placeholders are now presented in nested menus like Ticket » Latest Message » Sender » Organization » Name. It's much, much simpler. We're looking forward to breezing through those examples during training sessions in the future.
There are a lot of palpable improvements in this release. There just as many "under the hood" improvements to keep things running efficiently, on the most modern hardware, with less frustration, as building blocks for all kinds of future functionality. We have a huge pile of feedback, plenty of big ideas, and no intention of slowing down.
Thanks for supporting Cerb!
- Jeff Standen, Software Architect, Cerb
Important Release Notes
-
To honor our commitment to 3-4 major updates per year for annual subscriptions, we are backdating the release date of 7.2 for licensing purposes to May 1, 2016. Visit the project website to purchase or renewal a license.
-
Always make a backup before upgrading.
-
To upgrade your installation, follow these instructions.
-
If you use the Web API for integration, note that the
is_waiting,is_closed, andis_deletedfields onticketrecords are now stored in thestatusfield.
Changes
- Quick Search
- Cards
- Workspaces
- Incremental bulk update for large worklists
- Improved the usability of broadcast placeholders
- Broadcast from contact worklists
- Broadcast from worker worklists
- Broadcast from organization worklists
- Custom fields in worklists are much more efficient
- Dashboard widgets load faster
- Improved field selection on worklist export
- Miscellaneous worklist improvements
- Added a primary email address to organizations
- Localization fields on contacts
- Bulk update watchers on contact worklists
- Bulk update more fields on worker worklists
- Condensed the active workers list
- Improvements when importing ticket records
- Virtual Attendants
- Search
- Mail
- Improved placeholder usability in signatures
- Improved ticket status performance
- Improvements to email headers performance
- Full original headers in message records
- Logging message headers in the email parser
- Faster message threading performance in the email parser
- Improved email parser efficiency
- Track the last checked time on mailboxes
- Usability
- Tasks
- Snippets
- Profiles
- Portals
- Notifications
- Setup
- Reports
- Web API
- Plugins
- Platform
Quick Search
Completely overhauled the quick search interpreter to enable more expressive queries. This is simpler for workers, saves a lot of work for third-party developers, promotes a consistent syntax across filters, and is far more flexible when adding new functionality.
Group worklist filters with AND and OR
Previously, all the filters added to a worklist were in a single AND group. Additional filters could only further narrow down the current results. There was no way to join the results of two independent filters.
It is now possible to add any number of filters in arbitrary groups using AND and OR keywords. By default, AND is used when an operator isn't specified.
Parentheses are used to define a group of filters, and groups can be nested within other groups.
For example, a very common request is for a worklist that displays tickets either owned by OR watched by the current worker. This previously required two worklists. It can now be accomplished with this quick search:
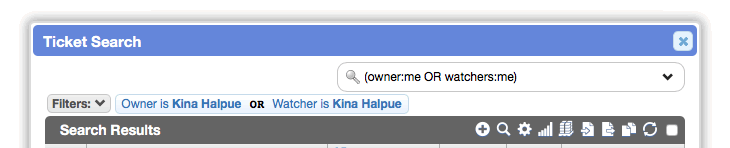
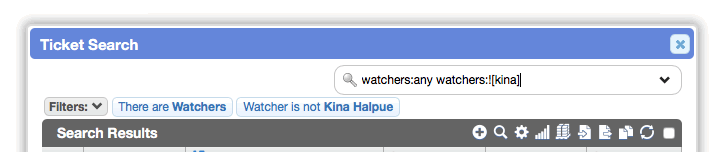
Similarly, you can display a worklist of tickets that have at least one watcher BUT exclude any records watched by a particular worker:
Filter with an array of values
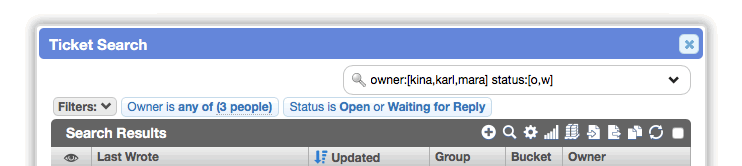
Previously, some filters allowed an array of values, but it was never made clear when this was possible, and the format wasn't standardized.
Now you can specify an array of values by including them within brackets and separated by commas:
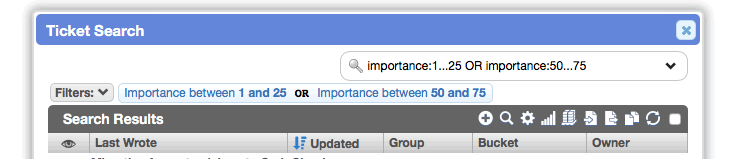
Filter using ranges of numeric values
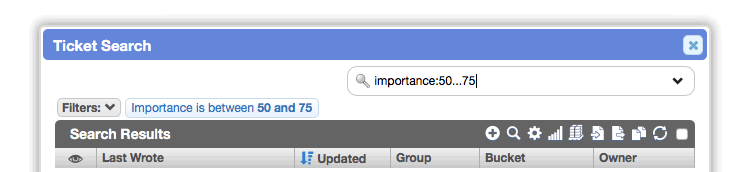
Previously, you could only filter a numeric value using greater than or less than.
You can now specify a range of values by separating the lower and upper (inclusive) boundaries with an ellipsis (...):
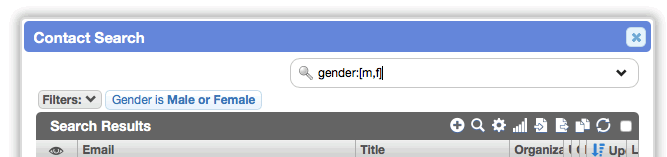
Filter using negation
Previously, some filters supported negation, but this was also inconsistently handled.
Now you can specify a negated filter by using an exclamation mark (!) as the first character of the value:
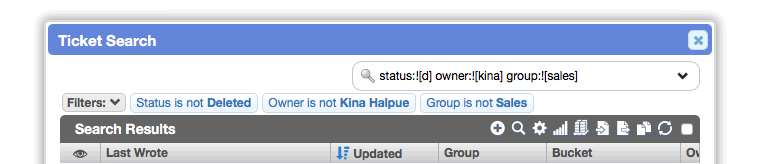
Apply the same filter multiple times
Previously, each filter could only be used once per worklist. This made it difficult or impossible to handle some queries (e.g. "any value from 10 to 20, but not 15").
You can now apply the same filter any number of times.
For instance, you can find records without an owner OR where you are the owner:
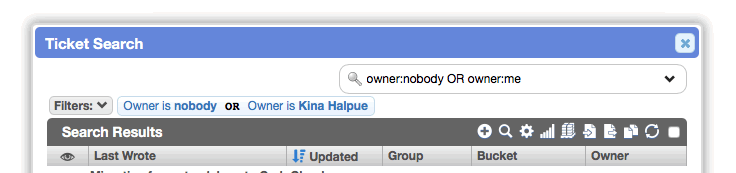
You can also filter non-continuous ranges:
Improvements to fulltext searching
Any search text without an explicit field: prefix is considered to be part of a text-based search. Quoted phrases in quick search queries may contain any characters other than extra quotation marks.
Boolean operators are now supported regardless of the search engine in use (e.g. word OR "phrase two").
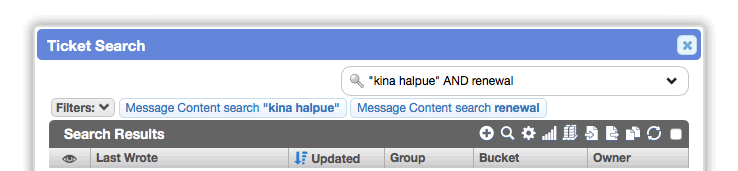
Fulltext search results provide more information
When performing a fulltext search on a worklist, meta information is now displayed above the worklist for each search (search engine, query time in milliseconds, total results). If more results were found than returned, a "try being more specific" message is given. This should help address usability issues when using search engines like Elasticsearch (returning 500-1000 results) where it wasn't previously clear that partial results were being returned.
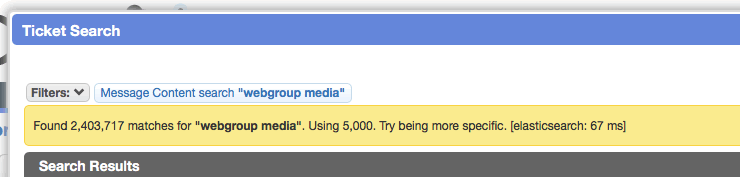
Improved quick search hints menu
Previously, the hints for quick search were found in a drop-menu that had to be opened and closed manually. Now the syntax and available filters are autocompleted while typing. Previously, inserting filters from the menu only appended to the end of the text box. Now, autocomplete suggestions will be inserted at the cursor position. Autocomplete situations are now also aware of the content around the cursor.
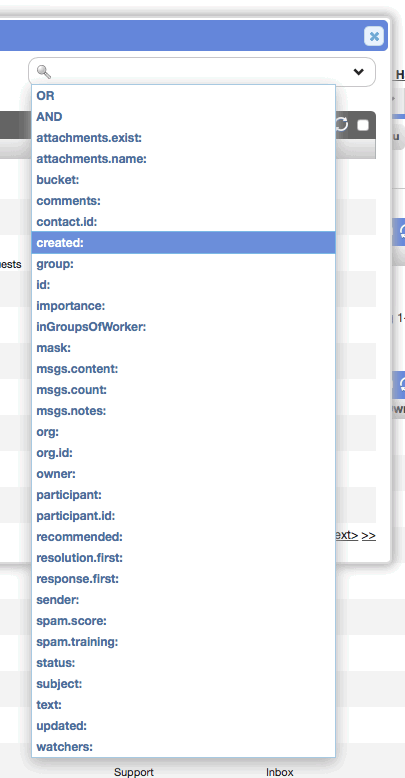
Cards
Customizable fields on card popups
[CHD-4353] We've received many requests for the ability to add other built-in and custom fields to the card popups. Previously, the displayed fields were hardcoded and couldn't be changed without hacking around in the code.
From 'Setup->Configure->Cards', admins can now configure the default fields that show up on card popups for every record type:
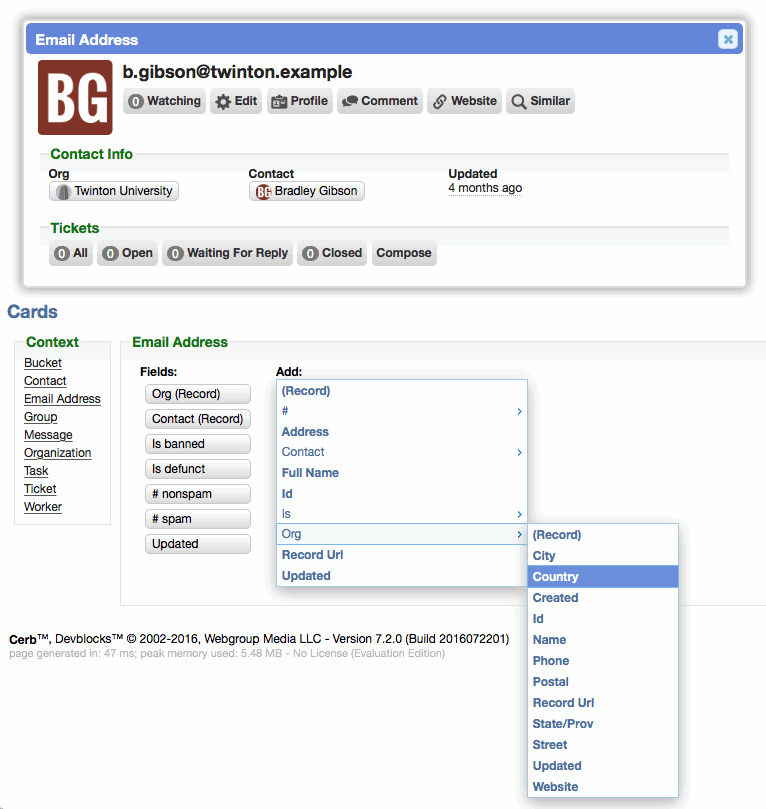
Quickly compose new messages from cards
[CHD-4386] When viewing an address card popup, a 'Compose' button is now available in the 'Tickets' section. Clicking this buttons opens the compose dialog and pre-fills the email address in the 'To:' field:
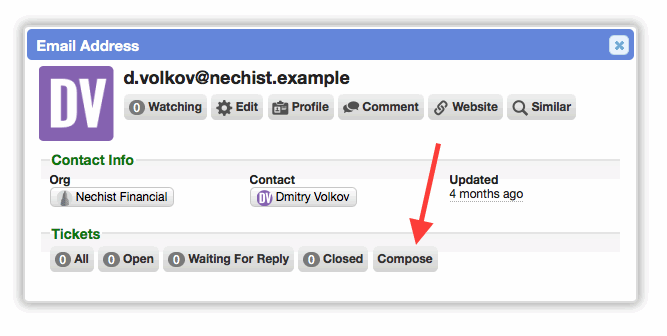
When viewing a contact card popup, a 'Compose' button is now available in the 'Tickets' section. Clicking this buttons opens the compose dialog and pre-fills the email address in the 'To:' field.
When viewing an organization card popup, a 'Compose' button is now available in the 'Tickets' section. Clicking this buttons opens the compose dialog and pre-fills the org name in the 'Org:' field, which provides autocomplete suggestions of the most common contacts from that org.
Card popup for task records
Implemented card popups for task records. Previously, the peek for task records always opened in edit mode.
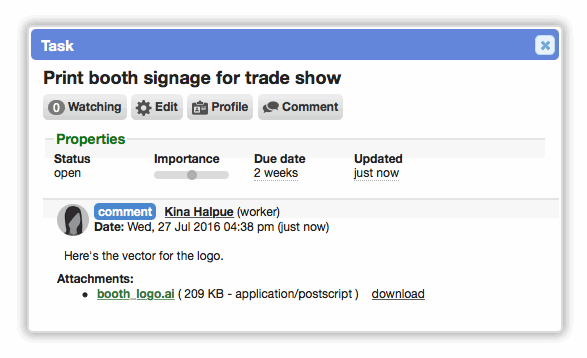
Comment timelines on card popups
When viewing a card popup you can now quickly view all the comments on the record. You can also add a comment using the new 'Comment' button at the top. After commenting, the comments timeline will automatically refresh.
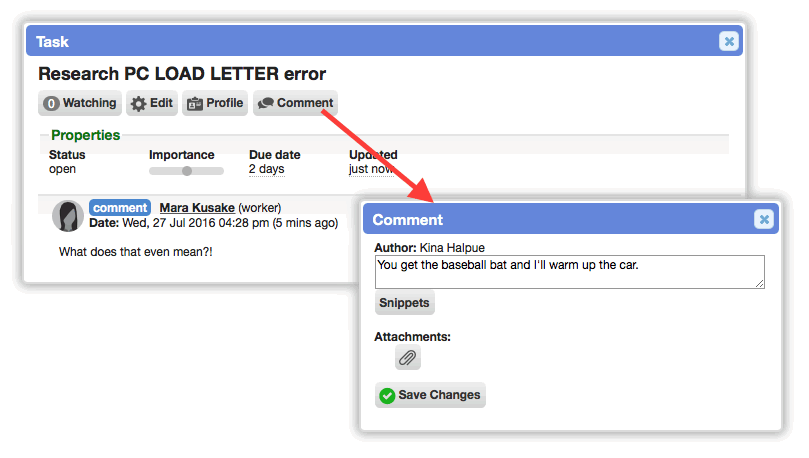
Workspaces
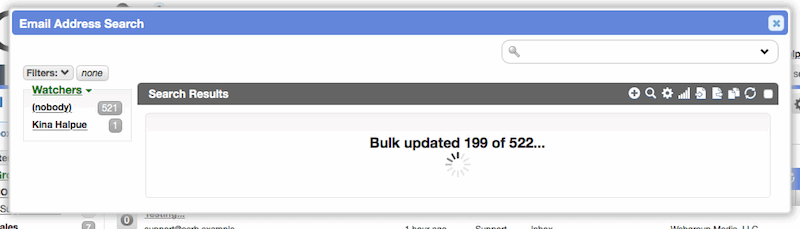
Incremental bulk update for large worklists
Improved bulk update functionality on worklists. Previously, the bulk update attempted to complete in a single request, which often timed out on the server, leaving the worker unsure if it completed or not (whether it did depended on PHP/MySQL configuration). Now, bulk updates run small batches of records with real-time progress shown above the worklist. Upon completion, the worklist will refresh as expected. The new process properly handles the updating of thousands of records.
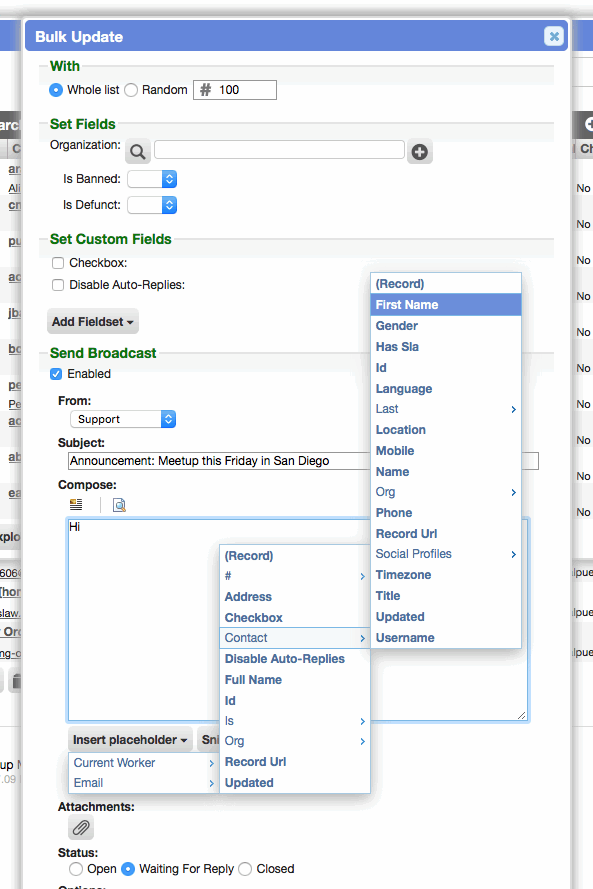
Improved the usability of broadcast placeholders
When broadcasting from a worklist, the available placeholders now display in nested menus rather than a very long list. This significantly speeds up the process of finding the desired placeholder.
Broadcast from contact worklists
Implemented broadcast functionality in bulk update for contact worklists.
Broadcast from worker worklists
Implemented broadcast functionality in bulk update for worker worklists.
Broadcast from organization worklists
Implemented broadcast functionality in bulk update for organization worklists.
Custom fields in worklists are much more efficient
Significantly improved the performance of worklists that use many custom field columns. Previously, custom field columns had a linear cost in the database (more columns meant more complexity). Now this cost is constant, and the custom field values are "lazy loaded" (they are all loaded with a single query and only when requested, and then merged with the original search results). Any number of custom fields may now be displayed as columns without negatively impacting performance. If a custom field column is used to sort the worklist, we still retrieve it with the original search results to make that possible.
Improved the performance of multi-value custom fields when used as NOT IN filters on worklists. These fields have a special condition where the presence of any of their fields in a "NOT IN" should exclude the field entirely, even if other values exist.
Dashboard widgets load faster
Dashboard widgets now load in parallel. Previously, dashboard widgets all loaded serially (i.e. one at a time). Now, up to three widgets will load at the same time.
Improved field selection on worklist export
When exporting from a worklist, the field chooser now uses nested menus to simplify selection. The default fields for each record type is also automatically selected.
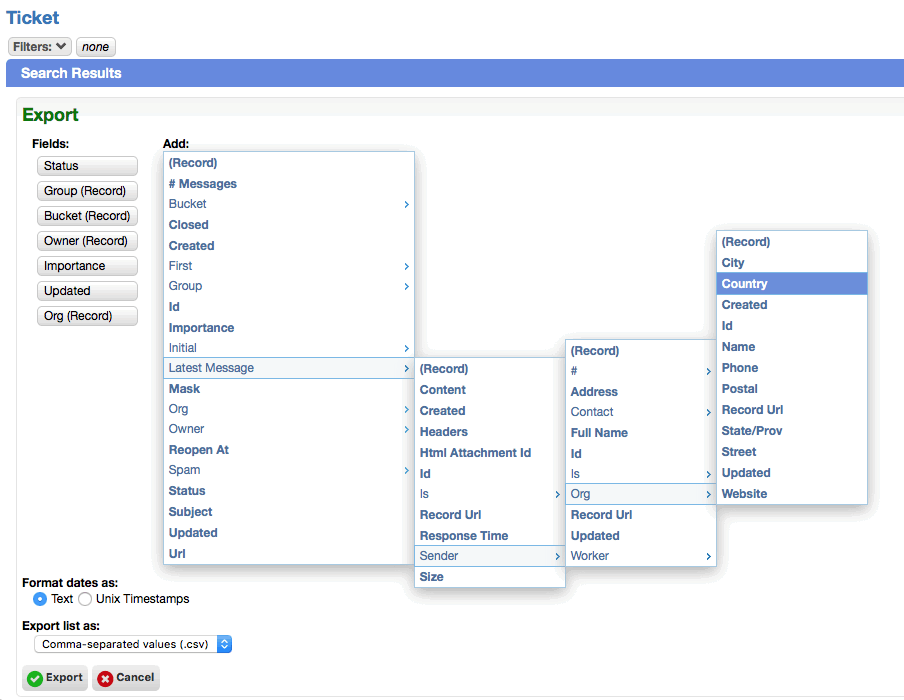
Miscellaneous worklist improvements
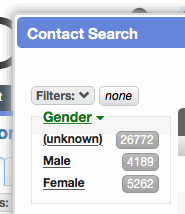
- [CHD-4330] Contact-based worklists can be subtotaled on gender.
-
Worker-based worklists can be subtotaled on gender.
-
Removed the 'Last Action' column on ticket worklists in favor of 'Last Wrote'. The same functionality can be added back through Virtual Attendant worklist behaviors.
-
Significantly improved the performance of filtering by watchers on worklists.
-
Improved the performance of ticket worklists when filtering by
participants:(particularly when filtering for participants with a *@host wildcard). -
Contact-based worklists can be quick searched by
gender:.
-
Worker-based worklists can be quick searched by
gender:. -
Added a
comments:filter for searching comments on contact worklists. -
Added a
va:filter for searching by Virtual Attendant in scheduled behavior worklists. -
Added an
inGroupsOfWorker:filter to ticket worklists. -
On ticket worklists, the
resolution.first:andresponse.first:filters now accept dates in natural language, like "< 1 hour" and "2 hours … 8 hours".
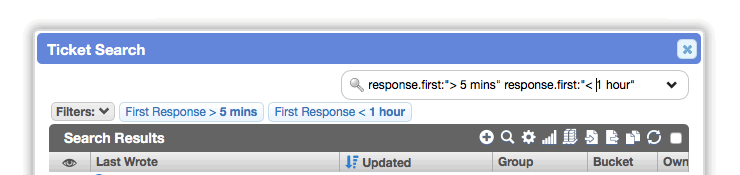
- On message worklists, the
responseTime:filter now accepts dates in natural language, like "> 1 hour" and "2 hours … 8 hours".
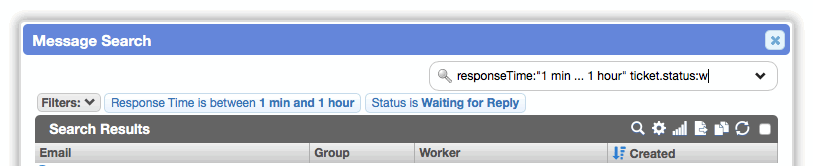
-
[CHD-4375] In message worklists, added a
header.messageId:quick search filter for matching messages based on their 'Message-Id:' header. This is particularly useful for webhook behavior from Mailgun, where the message-id header is the only identifier available. The filter will only return exact matches. -
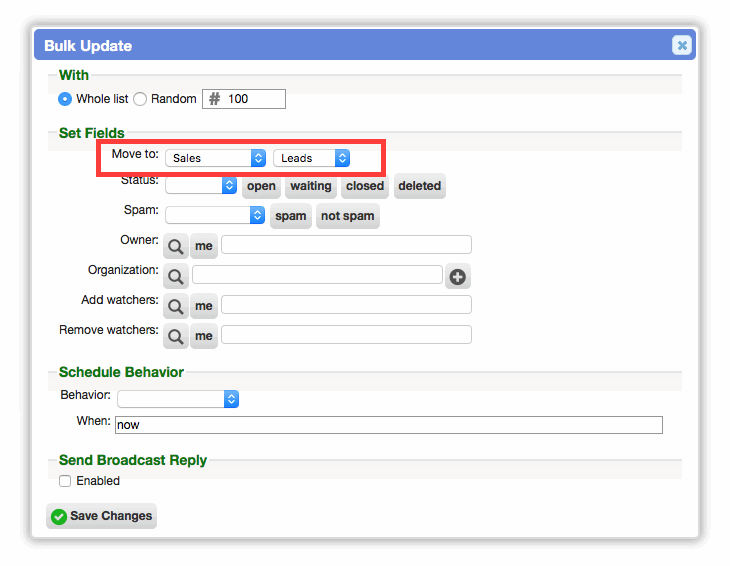
On ticket worklists, the bulk update popup now uses linked dropdowns for group and bucket in the 'Move To:' option. Selecting a group in the first dropdown displays its buckets in the second dropdown. Previously this was a huge list of "Group:Bucket" options.
-
Removed the 'pile sort' option from ticket worklists. This can be handled with subtotals and bulk update in modern versions.
-
When using bulk update from an organization worklist, the country field now autocompletes using existing values.
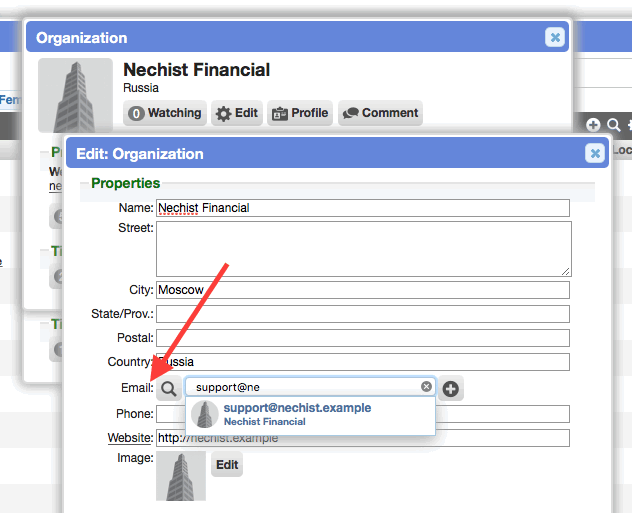
Added a primary email address to organizations
[CHD-4370] Added a primary email address field to organization records.
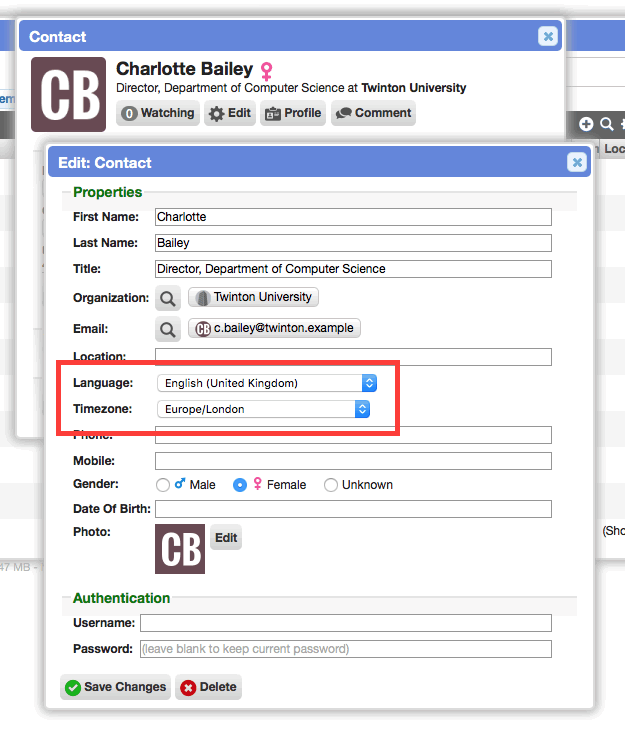
Localization fields on contacts
Added 'language' and 'timezone' fields to contact records. These provide for localization in community portals, and improved segmentation in worklists and reports.
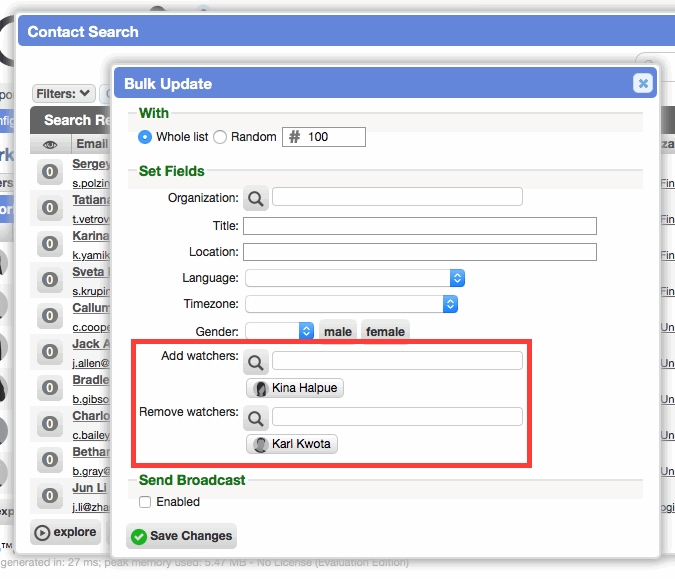
Bulk update watchers on contact worklists
When bulk updating contact worklists, watchers can be added and removed.
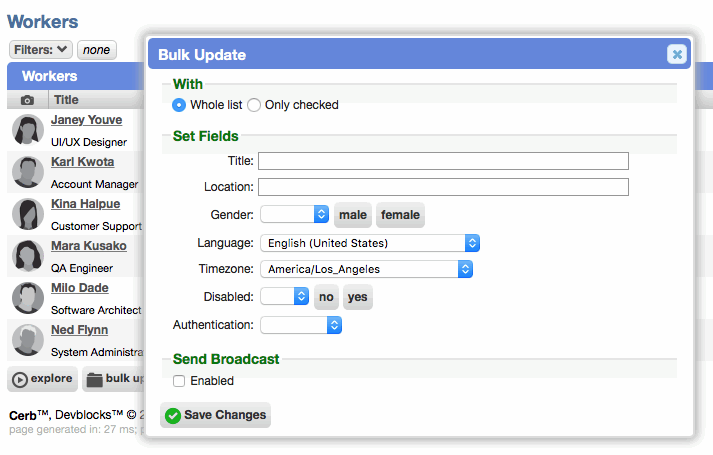
Bulk update more fields on worker worklists
When bulk updating a worker worklist, the following fields may now be set: title, location, gender, language, and timezone.
Condensed the active workers list
The "Who's Online" section now has a smaller footprint. Previously, every worker was listed on a separate line with their IP, idle time, and last activity. This information (and much more) is now available in worker cards. Workers are now listed as links (to cards) in a paragraph and separated by commas.

Improvements when importing ticket records
-
The
<is_waiting>and<is_closed>fields no longer exist in the schema. These should be replaced with<status>with a value of: open, waiting, closed, or deleted. -
The
<is_outgoing>element can be provided for all message records. This removes the requirement that sender addresses are set up beforehand and match. -
The raw message headers can be provided in the
<headers>element as a CDATA text block (rather than itemized elements per header/value pair). -
The
<org>element is available to create/link an organization to the ticket.
Virtual Attendants
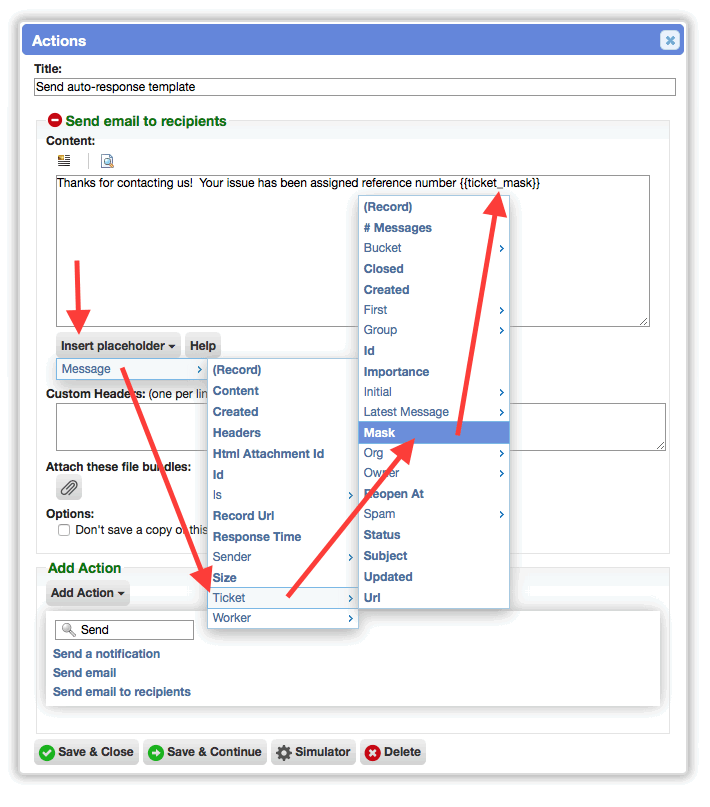
Improved the usability of placeholders in conditions and actions
When editing Virtual Attendants, the 'Insert Placeholder' button now opens a nested menu with related placeholders grouped together. This replaces a flat list with hundreds of options.
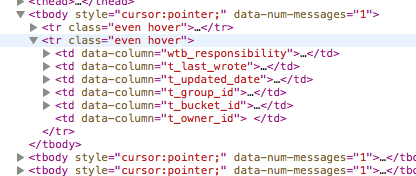
Simpler worklist behaviors
All worklists now have improved markup to simplify Virtual Attendant behaviors that target specific columns. A data-column attribute is available on each table cell.
Search
Improved search performance
Improved the performance of fulltext search filters when using the default MySQL Fulltext search engine. As of MySQL 5.6+, both MyISAM and InnoDB database tables support fulltext indexes. Prior to that only MyISAM supported fulltext, and that was how Cerb was developed and benchmarked.
Our testing has shown InnoDB to generally be faster when matching terms ('all these words'), but significantly slower for matching phrases, especially in datasets with millions of rows (as is the case in many Cerb environments).
We've discovered many "exact phrase" searches in Cerb Cloud that took less than a second with MyISAM which are taking minutes in InnoDB. This has do with the fact that InnoDB uses distributed indexes and doesn't currently support a LIMIT clause to stop once the desired number of matches are returned.
By moving phrase searches into Cerb (using the index to match all the words in any order, then a LIKE for the exact phrase), we're able to make those slower searches in InnoDB more than 100X faster. This change also speeds up non-phrase searches, even against MyISAM tables.
Improved search relevance
Previously, when building search indexes for the MySQL Fulltext engine, we heavily pre-processed content to convert to lowercase, remove punctuation, remove reply-quoted content, remove common ("stop") words, remove accents, etc. This resulted in more efficient indexes, but it also reduced search accuracy. It also prevented some phrase searches from matching properly. Now all we do is strip reply-quoted lines and truncate content to the first 5KB. This only applies to content indexed after the 7.2 upgrade, so a full reindex should be performed if you need to search older content this way.
When using a fulltext search filter on a worklist using the MySQL Fulltext search engine, the query will now be pre-processed to conform to MySQL's requirements. Terms that are smaller than 3 characters or larger than 82 are ignored, as are words that appear in the default InnoDB "stop words" list. This is because the presence of any of these terms in an "all these words" search would return 0 results instead of being ignored by MySQL.
Improved InnoDB Fulltext support
-
A new
APP_DB_ENGINE_FULLTEXToption is available in the framework.config.php file. This specifies the MySQL database engine that should be used for newly created fulltext search tables. In MySQL 5.6+, 'InnoDB' now supports fulltext indices. Previously, only 'MyISAM' tables supported them. This is particularly important at scale since InnoDB is recommended (or even required). -
APP_DB_ENGINE_FULLTEXTnow defaults toAPP_DB_ENGINEwhen not explicitly set inframework.config.php. If this results in InnoDB being selected in MySQL versions prior to 5.6, then MyISAM is always used regardless of this setting. -
The installer now checks if the MyISAM storage engine is disabled and the MySQL version is less than 5.6 (where InnoDB has fulltext indexing). If the MySQL version is >= 5.6 then the installer will succeed with InnoDB handling everything.
Improved Elasticsearch integration
-
Fixed an issue where newer versions of the Elasticsearch search engine couldn't be configured.
-
Condensed search schema document indexing into a single 'content' field. This is what the MySQL Fulltext search engine did anyway, and Elasticsearch doesn't need the inefficient
_allfield with this approach. Cerb already provides filters for everything else. -
When configuring Elasticsearch, a "default query field" option is now available. This makes it possible to disable the
_allfield in an Elasticsearch index to save resources (up to a 50% reduction). In most cases, Cerb writes to an aggregated 'content' field rather than itemizing fulltext search fields. -
Added default timeouts to searches using the Elasticsearch engine. The indexing timeout is 20 seconds and the query timeout is 5 seconds.
-
When performing fulltext searches using Elasticsearch, a 'max results' setting over 1000 results now joins a temporary table. When returning fewer than 1000 results, the more efficient inline
IN(...)method will continue to be used. -
Added a helper script to
install/extras/developers/search_dump_elasticsearch_json.phpto assist with bulk importing message content from Cerb into Elasticsearch.
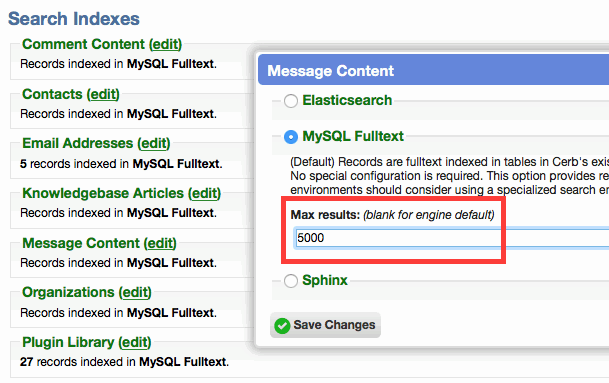
Limit results for all search engines
- All search engines (MySQL FT, Sphinx, Elasticsearch) can now provide a 'max results' option.
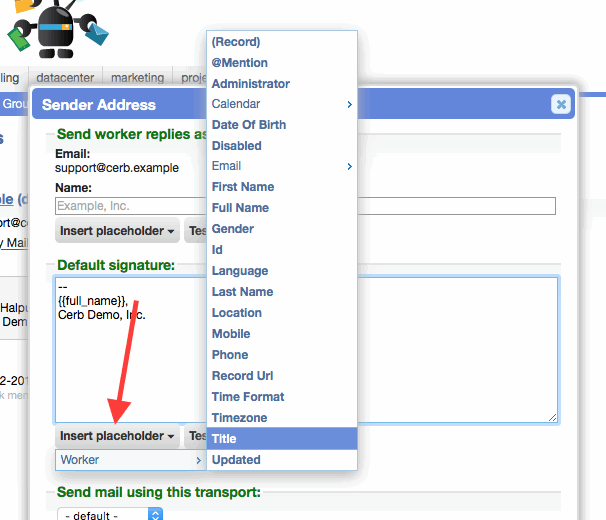
Improved placeholder usability in signatures
- When editing signatures on sender addresses in Setup, the 'Insert Placeholder' button now uses nested menus rather than a huge dropdown list of placeholders.
-
When editing signatures on bucket records, the 'Insert Placeholder' button now uses nested menus rather than a huge dropdown list of placeholders.
-
When editing HTML templates in Setup, the 'Insert Placeholder' button now uses nested menus rather than a huge dropdown list of placeholders.
Improved ticket status performance
Optimized the way the status field is stored for ticket records in the database. Previously, there were three different fields and indexes involved (is_waiting, is_closed, is_deleted), as a byproduct of continuous improvements over many years. These fields have been consolidated into a single status_id field. This should result in slightly faster ticket worklist results, slightly less filesystem space wasted, and much cleaner logic in the code.
Improvements to email headers performance
Improved the performance of operations involving email message headers (e.g. to/from/subject/date/etc) and made them much more efficient in the database.
Previously, each header/value pair was saved as a separate row in the message_header table. Since each message has many headers, the record count of the headers table grew exponentially larger. For instance, one sampled production Cerb environment had 1.7 million messages and 42 million message headers (an average of 25 headers per message). The access times of the message_header table could be negatively impacted at scale. Additionally, since message headers are immutable (never modified and never appended to), it made little sense to store headers individually.
Cerb now stores all of the headers for a message together in a single row, making reading and writing a single operation and result. The 7.2 update automatically migrates existing records to the new format. The overall size of the data in the table should be relatively unchanged, but the size of the indexes is significantly reduced since the header names and first few characters of each value no longer need to be indexed.
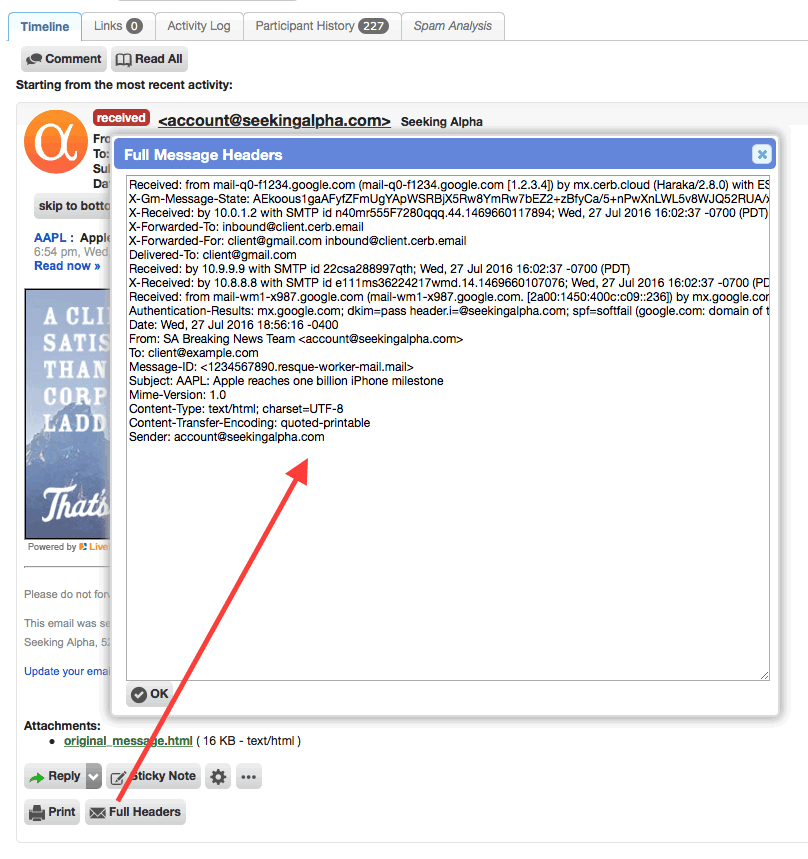
Full original headers in message records
Previously, when viewing a ticket profile, messages could be toggled to show "brief" or "full" headers above the content. However, the "full" version of these headers was not the original copy – it was decoded, de-duped, etc. The raw original headers are now stored for each message, and can be accessed from the "Show Full Headers" button in the extended "…" options at the bottom of each message. The original headers are shown unformatted in a popup, rather than expanding above the message, which makes it easier to inspect and copy them. Whenever these headers are used in Cerb (displayed on messages, in Virtual Attendants, etc) they are decoded in real-time. This allows the handling of header information to change and improve without modifying their original state.
Logging message headers in the email parser
When the 'cron.parser' scheduler job runs to process incoming mail, it will now log output for several important headers (e.g. To, From, Subject, Date, In-Reply-To, Delivered-To) to assist with later troubleshooting and forensics. Previously, only the file name of the parsed message was logged, unless Virtual Attendants ran conditions against specific fields.
Faster message threading performance in the email parser
Improved the performance of threading replies to conversations.
Previously, Cerb used a MySQL header_value prefix index on the message_header table for lookups. This was inefficient for several reasons:
-
All of the stored headers wrote to the same index, not just 'message-id'
-
The value of 'message-id' wasn't guaranteed to be well distributed (there could be millions of rows with the same prefix); etc.
The Message-ID: header of each message is now converted to a SHA-1 hash and stored on the 'message' table. It's now much faster when matching an incoming In-Reply-To: or References: header against these values. The SHA-1 hash is a fixed length (40 characters), and even very similar (but different) values will end up having very different hashes, which allows us to more efficiently index only the first few characters of the hashes for lookups. In high-volume environments with database contention (e.g. locks), message_header lookups were often implicated, and this should no longer be an issue.
Improved email parser efficiency
-
Refactored the email parser to be more efficient. Replaced the direct usage of the
mailparse_*API in PHP with Mailparse'sMimeMessagewrapper class. This simplified the ability to parse email messages as either files or text-based variables and cleaned up a lot of code. Previously, Cerb always wrote email messages to the filesystem before parsing (i.e. Support Center, REST API), which generated needless filesystem I/O (much slower than memory). -
In the inbound email parser, the enforcement of the maximum attachment size is now more efficient. Previously, the attachment was always written to disk before the size was checked and the file potentially discarded. Now, if a
Content-Disposition-Size:header is provided, this can be used to ignore an attachment before doing anything else with it (saving compute cycles, filesystem I/O).
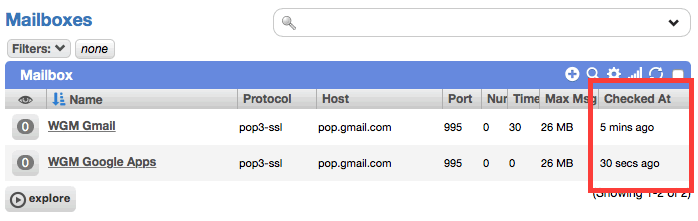
Track the last checked time on mailboxes
[CHD-4188] Mailbox records now keep tracked of their 'last checked at' timestamp. This is used to check mailboxes in the order of least recently checked first, which addresses issues where a slow or busy first mailbox could block other mailboxes from ever being checked.
Usability
-
Improved the usability of the 'skip to bottom' link on each message in a ticket profile. This link was designed to make it easy to jump to the message actions when viewing a large message; however, it displayed on all messages. This button will now only show up when the message actions (like 'Reply') are scrolled beyond the bottom of the browser's current viewport. This saves some screen space and reduces clutter when reading shorter messages.
-
[CHD-4396] When sending HTML mail, improved the way that Markdown-formatted lists are converted back to plaintext.
-
[CHD-4329] When viewing a ticket timeline, if a message sender has an organization but not a contact, the organization details are now displayed along with a card popup.
Tasks
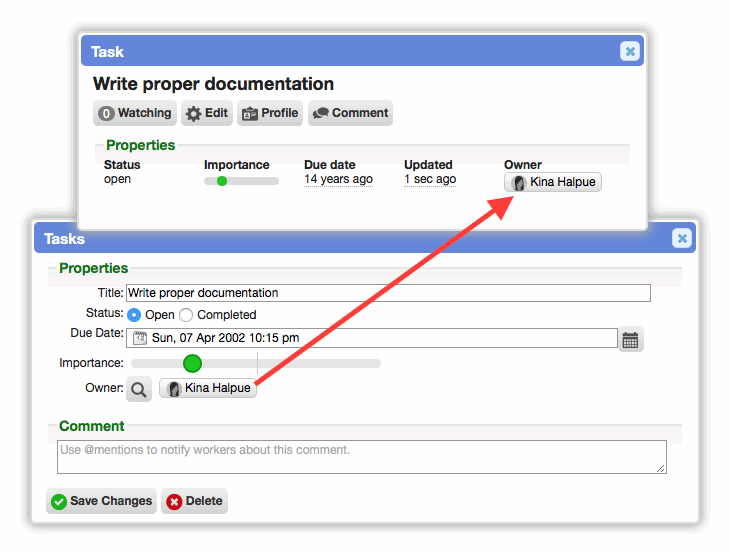
Task records have an owner field
Task records now have a built-in 'owner' field to simplify worker assignments. Previously this required the use of a worker-based custom field.
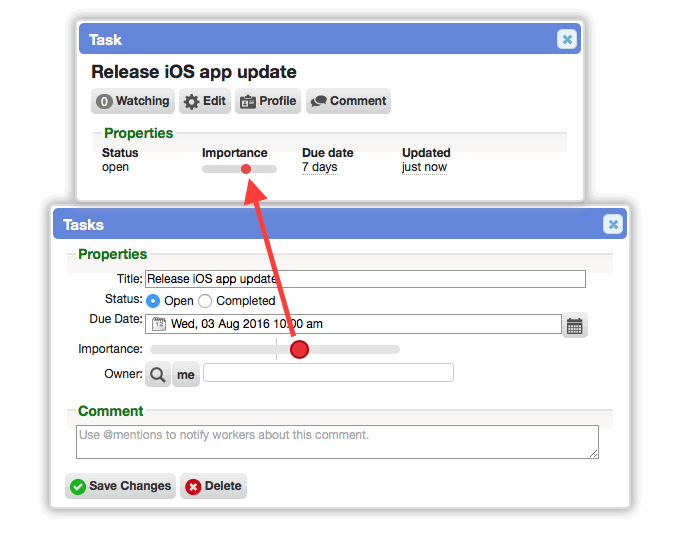
Task records have an importance field
[CHD-4226] Task records now have a built-in 'importance' field that behaves like the same field on ticket records. This allows for simpler prioritization of tasks without requiring the use of custom fields.
Snippets
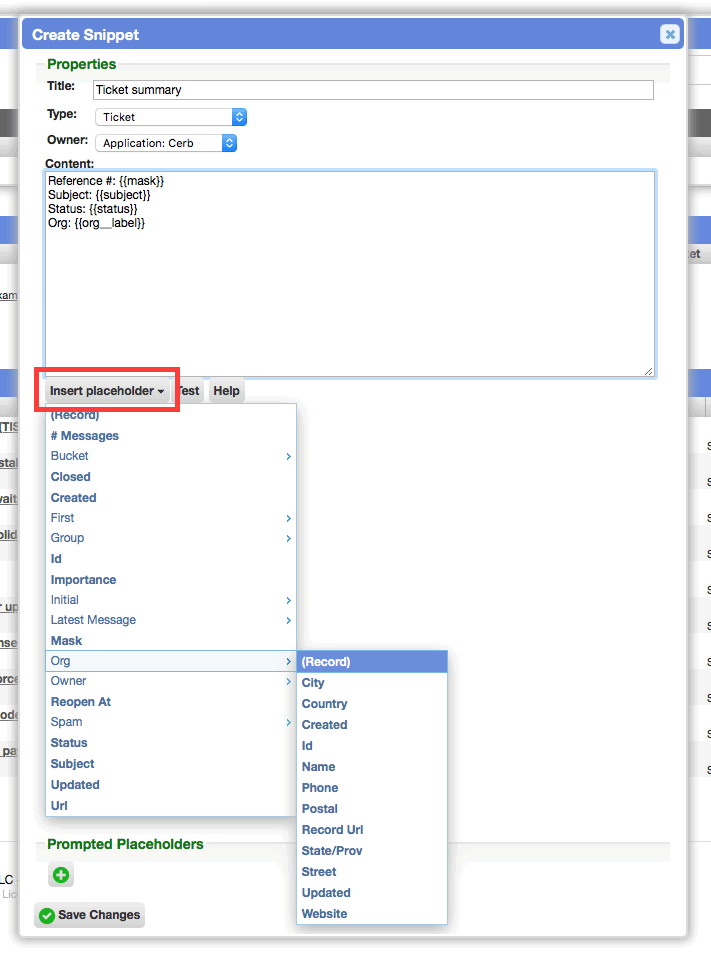
Improved placeholder selection in snippets
When editing snippets, the 'Insert Placeholder' button now opens a nested menu rather than a flat list with hundreds of options.
Creating snippets using selected text
[CHD-4415] When opening the 'Create Snippet' popup from compose or reply, any selected text in the current message will be used as the snippet's default text. Previously, this content had to be copied manually in a second step.
Profiles
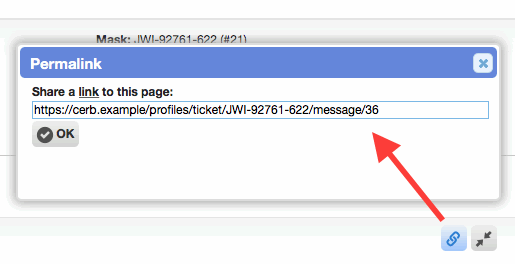
Improved permalinks on profiles
Improved the usability of permalink buttons on profiles. Previously, clicking a permalink button redirected the browser instantly to the permalink URL, which was often undesirable (e.g. when in the middle of a reply). These buttons didn't allow copying the URL in all browsers (Firefox in particular). Now, clicking a permalink button opens a popup which displays the permalink URL, already selected and ready to copy. This doesn't prevent a worker from continuing what they were doing by redirecting them to something else, and it makes it much easier to share these URLs.
Activity Log
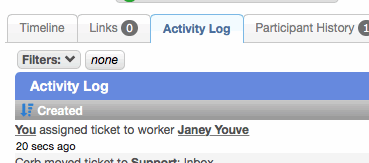
In the activity log, when a ticket is assigned to a worker, that worker's name is now a clickable link to their profile.
Portals
Performance
-
Added a cache for community portal records. Previously, these results always came from the database.
-
Improved the performance of loading templates from plugins. Previously, the content of the referenced templates was being loaded every request. Now they are only loaded when their modification times have changed.
-
Previously, when custom templates in Community Portals (like the Support Center) were modified, the entire template cache was flushed. Now only the cache of that specific template is removed.
Usability
- Added an error message when attempting to add a community portal and no portal extensions are enabled.
Security
- Custom templates in the Support Center now run in a secure sandbox.
Notifications
Changes to the notifications popup are saved
[CHD-4266] The unread notifications popup now saves any changes made (e.g. filters, columns, subtotals, sorting).
Setup
Usability
Improved the organization of the Setup page. The 'Configure' menu now has subsections for System, Contexts (Record types), and Plugins. Virtual Attendants and Portals moved out of Configure into their own top-level menus.
Mailboxes
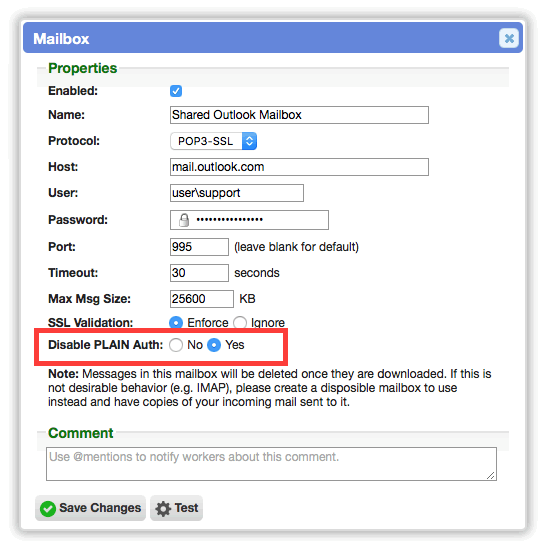
In Setup, when creating or modifying mailboxes, a new 'Disable PLAIN Authentication' option is available. This is necessary for proper authentication in some environments (e.g. shared mailboxes in Exchange/Office365).
Scheduler
-
Added an
ignore_internal=1option to bare scheduler /cron URLs. This ignores the built-in scheduler jobs (e.g. heartbeat, mailbox, parser, search, etc) and only runs plugin-provided scheduler jobs. This is useful when scheduling jobs independently by type. -
In the scheduler, added a
max_mailboxesURL option to /cron/cron.mailbox to control how many mailboxes are checked per job.
Sessions
In 'Setup->Configure->Sessions', the bulk update action for deleting sessions moved to a worklist action.
Reports
Added choosers to report filters
[CHD-4331] The 'Worker History over Date Range' and 'Group Replies over Date Range' reports now use the new chooser popups for filtering.
Web API
Add attachments to comments in the API
[CHD-4369] When creating a comment through the Web-API, attachments can now be added to the comment using one or more instances of the file_id[] parameter.
Plugins
Asset Tracking
- [CHD-3576] Implemented bulk update functionality on asset worklists.
Domains
- When sending a broadcast from a domain worklist, file attachments can be added to the messages.
Platform
Installer
[CHD-582] The installer now automatically adds the client's IP to AUTHORIZED_IPS_DEFAULTS in framework.config.php.
Updater
The Cerb automated upgrader will no longer close all worker sessions when updating. If a specific patch needs to force all workers to log back in (which should be rare), then it can explicitly do so. This change makes the upgrade process more seamless, less annoying for workers, and allows it to be automated.
Localization
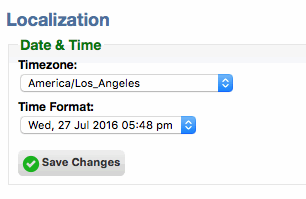
[CHD-4398] Added a global 'Timezone' setting to Setup->Configure->Localization. This serves as the default when a worker doesn't have a timezone set, or there is no session (Virtual Attendants, webhooks, etc). In many standalone deployments this wasn't necessary since the system timezone was sufficient as a default, but in distributed and multi-tenant environments we needed a per-instance default.
Performance
-
Worker 'last activity' is now determined by the activity log and sessions, and the separate mechanism from 4.x that wrote simple activity info directly to worker records has been removed. This is more efficient since it's not constantly invalidating the worker cache (previously even several times per minute). On worker peeks, when a worker has been active within 15 minutes, they're "currently active" rather than "active 49 seconds ago", which allows sessions to update more efficiently as well.
-
Optimized the database indexes for: address, attachment_link, comment, context_link, message, and ticket. This should reduce disk space usage and speed up writes.
Resiliency
-
Added
APP_DB_OPT_CONNECTION_RECONNECTSandAPP_DB_OPT_CONNECTION_RECONNECTS_WAIT_MSoptions toframework.config.php. These control the number of times, and duration between, that Cerb will attempt to reconnect to a prematurely closed database connection (i.e. one that had connected successfully at the beginning of the request). The first database connection when Cerb answers a new request ignores these options, and will fail instantly if the database is unavailable. These options are specific to situations where MySQL severs connections ("MySQL has gone away", "MySQL is shutting down", a long running query is killed from the MySQL console, etc). The option defaults to retrying 10 times with 1 second between attempts. In high traffic environments this could be tuned to fail quicker (and not hold load balancer or proxy connections open longer), and in lower traffic environments it could be tuned to retry longer (especially for a known flakey database host). Previously, if a database connection closed during a Cerb request, the subsequent queries in the same request would fail. It is now possible for Cerb to retry the previously failed query (when caused by the database host connection rather than SQL syntax errors) and resume/complete normally. -
When the database isn't running in writer/reader mode (read/write splitting), or when the replica connection fails and it falls back to master, Cerb is now more efficient about continuing with that assumption for the remainder of the request. Previously, the connection was re-checked multiple times.
-
Added some sanitization checks when writing to the server-side cache. Previously, it was possible for the cache to become poisoned with invalid results in some rare situations (e.g. "MySQL has gone away"). This could lead to difficult to troubleshoot issues, like legitimate logins returning "Invalid password".
Scalability
-
The
templates_cpath where Smarty compiles templates is now configurable in framework.config.php from theAPP_SMARTY_COMPILE_PATHoption. This is useful in multi-tenant environments where the template compile cache can be shared between instances (which reduces I/O on disk and memory usage in opcache). It also allows the template compile cache to be separated from other temp files, since the compile cache is frequently accessed and rarely changed, and it may not perform well on some shared filesystems (NFS, etc). Previously, this path was always located inAPP_TEMP_PATH. -
When Cerb displays an error and shuts down (e.g. "Cache not writeable", "Can't connect to database", "Access denied"), a proper HTTP status code is returned. Previously, a lot of these error messages still returned
HTTP 200 OK, which caused problems with detecting errors from distributed services like proxies, load balancers, and monitoring. -
Added
APP_DB_OPT_MASTER_CONNECT_TIMEOUT_SECSandAPP_DB_OPT_READER_CONNECT_TIMEOUT_SECSoptions in framework.config.php for independently controlling the timeout when connecting to the MySQL database(s). This previously used the system default, which was often 30+ seconds (way too long in distributed environments). The default timeout is now 5 seconds for the master and 1 second for the read replicas. This improve the gracefulness of fail-over capabilities in distributed environments. -
When a connection to the replica database fails (if defined), Cerb will now revert to the master. Previously a fatal error was returned which prevented the app from working at all. This change improves graceful fail-over in distributed environments.
-
Added a
DEVBLOCKS_CACHE_ENGINE_PREVENT_CHANGEoption to framework.config.php for preventing changes to cache configuration from Setup. When enabled, it also hides Setup->Configure->Cache. This option is useful when combined withDEVBLOCKS_CACHE_ENGINEto prevent Cerb's cache from ever touching the filesystem in a clustered environment. -
Added
DEVBLOCKS_CACHE_ENGINEandDEVBLOCKS_CACHE_ENGINE_OPTIONSoptions to framework.config.php for overriding the default cache in the platform. In a distributed environment with many web nodes and a shared filesystem, it can be inefficient for the initial cache (plugins, extensions, classloader, etc) to always be read from and written to disk-based storage, even when a memory-based cache (Redis/Memcache) is enabled. This occurs because the platform uses the cache before it has started up (cache engines are implemented as plugins, and plugins need to be loaded to use them). TheDEVBLOCKS_CACHE_ENGINEoption bypasses this. In our multiple web node tests against shared filesystems (NFS/EFS/RedisFS), connecting to Redis/Memcache directly rather than using an NFS/FUSE mount was over 400% faster. This is particularly useful for high-volume, high-availability installations and cloud hosting. -
Added a
DEVBLOCKS_STORAGE_ENGINE_PREVENT_CHANGEoption to framework.config.php for preventing changes to storage configuration from Setup. When enabled, it also hides Setup->Storage->Profiles. This is particularly useful in multi-tenant environments (like Cerb Cloud). -
Added a
DEVBLOCKS_SEARCH_ENGINE_PREVENT_CHANGEoption to framework.config.php for preventing changes to search configuration from Setup. When enabled, it also hides Setup->Configure->Search. This is particularly useful in multi-tenant environments (like Cerb Cloud). -
Added a
CERB_FEATURES_PLUGIN_LIBRARYoption to framework.config.php for enabling/disabling the Plugin Library feature in Setup. When disabled, it hides Setup->Plugins->Library, and doesn't attempt to fetch/install plugin updates during upgrades. This is useful in multi-tenant (Cerb Cloud) or intranet environments where the available plugins are curated manually, and potentially shared locally between multiple instances of Cerb. This is also useful in highly secure environments that want to prevent Cerb from downloading automatic code updates in a more user friendly way (currently these outgoing connections can just be firewalled). -
Added an
APP_SMARTY_COMPILE_USE_SUBDIRSoption to framework.config.php to toggle whether the template compile cache uses subdirectories for hashing (in ./storage/tmp/templates_c/). Enabling this option is more efficient than having thousands of cache files in a single directory. -
Previously, Cerb checked the contents of the
storage/_versionfile to detect changes to the underlying files (i.e. upgrades). This file just contained the numericAPP_BUILDas of the last time the upgrade process ran. Some OSes cached this content, but it could be inefficient when constantly loaded from distributed filesystems like NFS. This file has been renamed tostorage/version.phpso that it can be cached in shared memory via PHP opcache. It is recommend that the corresponding setting inphp.ini(opcache.enable_file_override=1) is also set to make thefile_exists()checks more efficient. -
The
DevblocksPlatform::redirect()andDevblocksPlatform::redirectURL()methods now accept an optional$wait_secsargument that intentionally delays the redirect. This is particularly useful in distributed environments where a change needs to be replicated for consistency (e.g. new sessions). -
Added the option
APP_DB_OPT_READ_MASTER_AFTER_WRITEto framework.config.php. This toggles 'master read-after-write' functionality to combat latency in read replicas when using read/write splitting for database queries. Previously, if a read replica was behind, then the UI could appear to be ignoring worker actions for a brief time. For example, several tickets could be selected in a worklist and then marked closed (writing to master), and when the worklist instantly refreshes those tickets could still appear open (reading from an eventually consistent replica). A subsequent manual refresh in this situation would show the current state of the data. This lag is only apparent to the worker who initiated an action, and not other workers who may see old data that's less than a second behind the master. This situation is more common when read replicas are distributed geographically away from the master with relatively slower network access. However, Cerb pages can load so quickly (tens of milliseconds or less), and read replicas can become busy with expensive queries no matter where they're located, so it was possible for this situation to occur anywhere. When this option is set to any non-zero integer value, reads will be redirected to the master following a write for that number of seconds within the current session. If a volatile memory cache is being used (Redis/Memcache vs disk), then reads in other requests (Ajax) will also be redirected to the master for the configured duration. The_DevblocksDatabaseManager::OPT_NO_READ_AFTER_WRITEflag passed to::ExecuteMaster($sql,$bits)bypasses this behavior for writes that tolerate eventual consistency. This option is disabled by default. -
Added a
APP_SMARTY_COMPILE_PATH_MULTI_TENANToption to framework.config.php for multi-tenant environments that share a single Smartytemplates_ccompile cache. When true, Cerb won't flush the template compile cache during upgrades or when enabling/disabling plugins. The default is false, which doesn't change Cerb's long-time behavior (these caches are flushed in several situations). -
Added a
APP_SMARTY_SANDBOX_COMPILE_PATHoption toframework.config.phpfor multi-tenant environments. This allows each tenant to have their own template compile directory; ideally on a shared filesystem, which solves issues with templates being out of sync across multiple web servers. -
Cerb no longer directly reads from the
$_SERVER['REMOTE_ADDR']value from multiple places. TheDevblocksPlatform::getClientIp()method now returns the client's IP. When multiple load balancers and proxies are involved, it's possible for multiple client IPs to be available (based onX-Forwarded-For), and Cerb now selects the appropriate one in these conditions.
Security
-
[CHD-4311] The
DEVBLOCKS_HTTP_PROXYoption inframework.config.phpnow configures a proxy for all outgoing HTTP requests. By default this uses an HTTP forward proxy, but the value can be prefixed withsocks5://to use a SOCKS5 server instead. This allows networked Cerb functionality to work behind a proxy: Virtual Attendant behaviors, Plugin Library, Widget datasources, avatar image URLs, Elasticsearch, etc. -
When using the PHP
open_basedirsetting, the logs complained aboutCURLOPT_FOLLOW_LOCATIONnot being available. We now handle following redirects in Devblocks.
Monitoring
Added a /debug/status page with stats in JSON format. This is useful for monitoring a Cerb instance.
Developers
-
Added
DevblocksPlatform::setRegistryKey($key, $value, $as, $persist)andDevblocksPlatform::getRegistryKey($key, $as, $default)methods for simpler access to the registry service. -
The Devblocks registry service now supports JSON as an object type. This can be used to store complex nested objects with automatic JSON encoding and decoding.
Dependencies
-
Patched the S3 library to support infrequent access (IA) objects and security tokens for temporary credentials.
-
Added the jquery.visible plugin to the platform. This detects whether a UI element is visible within the browser viewport or not.
-
Added the FineDiff library (by Raymond Hill, MIT license) to the platform. This makes it easy to create "diffs" for comparing historical revisions to blocks of text (like knowledgebase articles).
Import/Export
- Added a new ImpEx (Import/Export) tool to install/extras/impex/. The previous ImpEx tool was a separate project written in Java. This is written in PHP and is used from the command line. This makes the contribution of new export drivers much simpler.