Worklist Subtotals
worklist.subtotals
worklist.subtotals data queries run aggregate functions to categorize matching worklist records.
type:worklist.subtotals
of:tickets
by:[created@month,group]
format:timeseriesof:
The of: key specifies the type of records to subtotal.
of:ticketsby:
The by: key specifies which record fields to subtotal by.
Nested subtotals
Multiple fields can be separated with commas to generated nested subtotals (e.g. "tickets by owners by status").
by:[owner,status] Aggregate functions
The subtotal metric can be computed using different aggregate functions:
count(default)distinctavg,averagesumminmax
Functions target the last field specified in the by: list.
The count function is the default when no preference is given, and it can be target any field type.
The other functions may only be used against numeric fields. For example, you can't average group names, but you can average response times.
As of 9.0.7 the desired function is appended to the by: key following a period (.):
by.avg:[worker,responseTime] In earlier versions, a separate function: key was specified:
function:average
by:[worker,responseTime] This still works, but is deprecated.
Date histograms
Histograms can be generated for date-based fields by appending a unit of time following an at sign (@):
| Unit | Example |
|---|---|
@day |
2025-12-31 |
@dayofmonth |
31 |
@dayofweek |
Wednesday |
@hour |
2025-12-31 23:00 |
@hourofday |
23:00 |
@hourofdayofweek |
Wednesday 16:00 |
@minute |
2025-12-25 20:00 |
@minutes/5 |
2025-01-09 04:25:00 |
@minutes/15 |
2025-01-09 17:45:00 |
@minutes/30 |
2025-01-09 23:30:00 |
@month |
2025-12 |
@monthofyear |
December |
@quarter |
2025-Q4 |
@quarterofyear |
Q2 |
@week-sun |
2025-12-28 |
@week, @week-mon |
2025-12-29 |
@year |
2025 |
When using @week you can optionally specify if weeks should start on Sunday or Monday. The default is Monday.
by:[created@month,worker] Links
The by: fields can specify links or links.* (e.g. links.org) fields. This could create a report like "Sum of time tracking entries linked to organizations by month".
by:[links.org] Limits
When a field has only a few possible values we say it has "low cardinality". A ticket's status is one of four values: open, waiting, closed, or deleted. A checkbox is binary – it can only be true or false.
Conversely, some "high cardinality" fields have potentially infinite possible values. You may have millions of unique ticket subjects. There may be thousands of organizations in your address book. Your team may have hundreds of members.
You can limit the cardinality of a field by appending a tilde (~) to any by: field and providing a number. This only returns that number of the most common (top) values.
by:[created@month~10,org~25]Limit ordering
You can also return the least common (bottom) values by providing a negative number as the limit.
by:[group~-5] timeout:
The time limit of the query in milliseconds (0-60000). Default: 20000.
timezone:
(Available in 10.2.0 or later)
The timezone: key generates date labels in the given timezone location for bins like by:[created@day].
An option like timezone:America/Los_Angeles uses the offset UTC-7 or UTC-8 depending on Daylight Saving Time.
If omitted, this defaults to the timezone of the current worker or the server.
metric:
(Available in 9.0.7 or later)
The metric: key lets you specify an arbitrary equation to modify the calculated value for each row in the results.
In this equation, the metric value is represented by the placeholder x.
metric:"x*100"Mathematical operations
Basic mathematical operations are supported using + (addition), - (subtraction), / (division), * (multiplication), ** (exponents).
metric:"x**2"You can group operations with parentheses (()).
metric:"(x+2)*100"Filters
Numeric filters from bot scripting can be appended to a result following a pipe (|) character.
metric:"(x/4.33)|round"group:
(Available in 9.0.7 or later)
Occasionally you may need to treat nested subtotals as "samples" and calculate statistics using them.
Suppose you want the average weekly number of email replies sent per worker over the past month.
If you just use created@week:
of:message
by:[worker~20,created@week]
query:(created:"-1 month")…then you'll get back a row for every worker for every week in the past month. If there are 20 workers with 4 weekly samples, that's 80 rows.
You can use group: to flatten those results with a function:
of:message
by:[worker~20,created@week]
query:(created:"-1 month")
group.avg:[worker]This returns only a single row per worker, with the average count of their weekly samples over the past month.
The available functions are:
sum(default)avg,averageminmax
Like the by field, the function is appended to the group key following a period (.).
format:
The subtotaled worklist results can be returned in various formats:
-
tree (default) returns hierarchal data (a
nameandvaluefor each node, and a list ofchildrenfor branches). -
dictionaries returns a table-based format suitable for sheets and API results.
-
categories returns a series-based format suitable for bar charts.
-
pie returns data for use in pie and donut charts.
-
table returns tabular output, suitable for display with the 'Chart: Table' visualization widget. When nested subtotals are used, a row is returned for each distinct result (e.g. Support -> Kina, Support -> Janey).
-
timeseries returns series-based data suitable for a time-series chart (with the 'x' axis values as timestamps).
Examples
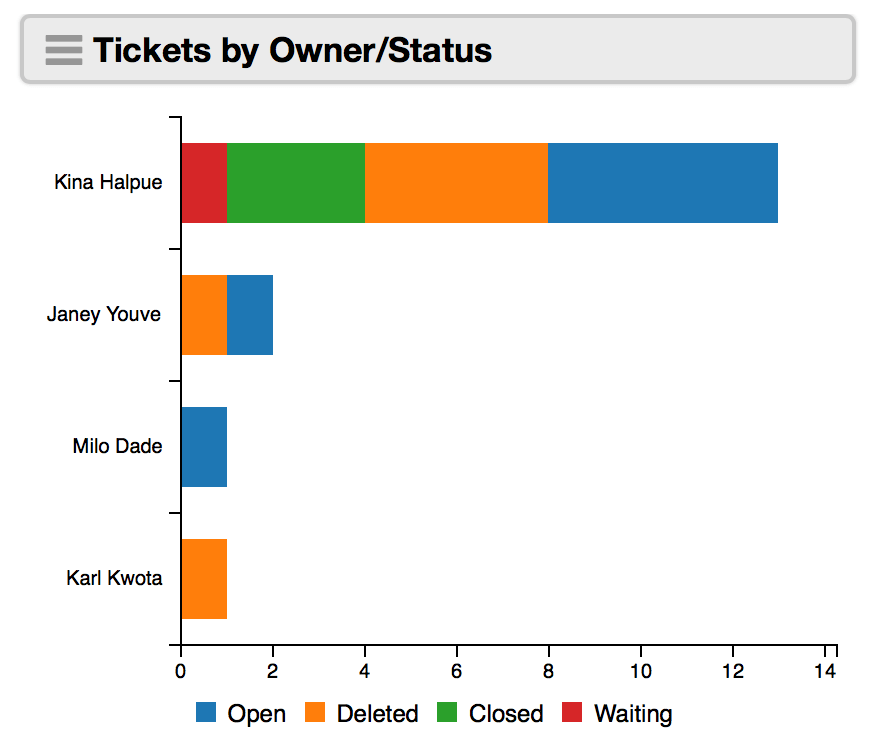
Return a stacked bar chart of tickets by owner by status
type:worklist.subtotals
of:tickets
by:[owner~10,status]
query:(owner.id:any)
format:categories