Cache
To optimize performance, Cerb caches frequently accessed but infrequently changed content. This significantly reduces database query traffic.
For instance, worker data is used on almost every page in Cerb, but you may go weeks without adding or modifying worker records. We cache worker records and invalidate the cache when one of the records changes. If you retrieve a list of tickets with an owner column, we can fill-in the worker information from the cache without requiring a potentially expensive JOIN in the database.
We use this approach in many other places as well: groups, buckets, sender addresses, bots, behaviors, etc.
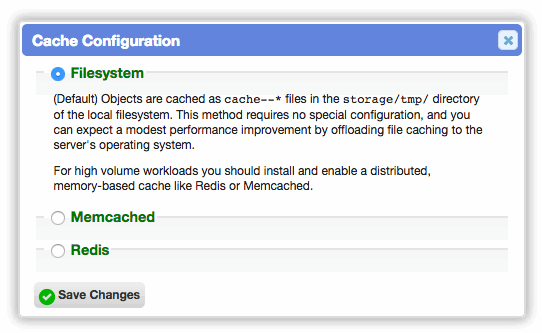
By default, Cerb saves cache files to the filesystem in the ./storage/tmp/ directory. The underlying operating system usually caches the contents of these files in memory anyway.
If you experience filesystem I/O bottlenecks, or you want to scale beyond a single web server, you may choose to set up a distributed cache using Redis1, Valkey2, or Memcached3. We support them all.
See also
- Guide: Scaling with Memcached
- Guide: Scaling with Redis
- Guide: Scaling with Valkey