Build a question answering chat bot with Cerb and ChatGPT
- Introduction
- Text generation using ChatGPT
- Connecting to the OpenAI API
- Create Beethoven Bot
- Managing FAQs in Cerb
- Add a new FAQ bot with your own topic
Introduction
In this guide we're going to build a chat bot that answers questions from a FAQ stored in Cerb. We'll index our FAQ for semantic search, and use that to teach ChatGPT new facts and improve its accuracy for niche topics it wasn't trained on. This is known as retrieval-augmented generation.
The goal is for you to create a bot that can answer common questions about your own organization or product. For demonstration purposes, we'll create Beethoven Bot to answer questions about music theory.
To follow this guide you will need to be an administrator in Cerb 10.4.3 or later. You can also install a copy of Cerb on your computer using Docker.

What is semantic search?
You're probably familiar with keyword search, where you find a list of matching documents using a few words or phrases.
Keyword search often uses an index, where the text from documents has been pre-processed for fast retrieval. A statistic (e.g. Term Frequency Inverse Document Frequency) then determines the best results by estimating the importance of terms within the collection of documents (the corpus).
This is relatively simple to implement, but it requires a query to use the same terms that appear in documents in order to find them.
For instance, you would need to specifically mention dark mode to find documents about it. This can be troublesome when exploring a new topic, since you may not know the proper terminology for what you're looking for.
An improved, modern alternative to keyword searching is semantic search. Rather than relying on specific phrasing, semantic search uses the relationships between words from a large language model.
Instead of the dark mode keyword, we can now use concepts like brightness, luminosity, contrast, or eye strain in our search query. With a multi-language model, we can even ask in different languages – like Nachtmodus (night mode) in German.
Large language models (LLMs)
Large language models (LLMs) train a neural network by processing enormous amounts of unstructured text (e.g. Wikipedia, books, websites, source code), and in the process they uncover relationships between words and phrases (e.g. parts of speech, grammar, synonyms/antonyms, taxonomy). This is a simplification of how a human brain works.
A neural network is a series of nodes (neurons) in layers, which are often visualized as adjacent columns. The first layer's inputs are sent through successive hidden layers and ultimately return an output layer. The weights (strengths) of the edges (connections) between nodes in adjacent layers are continuously adjusted during training – which we refer to as machine learning.

Modern large language models often use a more complex neural network architecture called transformers. This is beyond the scope of this guide, but it's helpful to understand that transformers allow the neural network to discover relationships between all words in the input text and not just adjacent or prior words.
The training can be supervised (including both example inputs and desired outputs), or unsupervised (only inputs are provided and patterns are discovered).
In an LLM, the inputs are usually a sequence of tokens – numeric representations of words or word fragments from the training vocabulary. This enables mathematical operations to be efficiently performed on natural language.
Tokens may be smaller than a complete word, which allows for handling unknown terms as a combination of letters, prefixes, suffixes, etc. The exact vocabulary depends on the training data.

Cerb is not a token in the vocabulary. It's a combination of the token prefix Cer and the token letter b. You may also notice that tokens contain leading whitespace to mark the start of a new word. The corresponding token IDs in this example are: [2061, 318, 17419, 65, 30]Text embeddings
Once an LLM is trained, it can be used to generate text embeddings – a vector of real numbers that plot arbitrary text in multidimensional space. This can be used to cluster related concepts together.
These embeddings are derived in various ways, but a common method is to use the last hidden layer of a neural network.
The OpenAI API returns a vector of (1,536) 32-bit floating point numbers for each text passage we send it.
While a higher dimension count may lead to better semantic understanding, it comes at a higher computational cost. An optional additional step could reduce the dimensionality to a more manageable size. For instance, from 1,536 dimensions to 768 or 384.
Comparing the similarity of text embeddings
Text embeddings are assumed to be more semantically related when they are closer together.
We can intuitively understand the distance between vectors in a few dimensions:
-
In one-dimensional space, the whole numbers
1and3have a distance of2between them. Despite there being a single whole number between them, it takes one step from1to2, and another from2to3. -
In two-dimensional space, the points
(1,1)and(2,2)have a Manhattan distance of2. They are1apart on the x-axis plus1apart on the y-axis. Their Euclidean distance is roughly1.414(a direct diagonal line ofsqrt(2)). For special cases like geospatial (GPS) coordinates, our distance function may need to account for factors like the Earth being an imperfect sphere. -
In three-dimensional space, coordinates include a third
zaxis (perhaps height) but are otherwise handled in a similar way. Simpler cases can compare vectors with Manhattan distance, Euclidean distance, dot product, cosine similarity (comparing angles between vectors), etc. -
In four-dimensional spatiotemporal space, we can consider an example of being at the same point on Earth at the same time (longitude, latitude, elevation, time). For instance, I could be standing at the top of the modern day Great Pyramid of Giza (
29°58′34″N 31°7′58″E) at an elevation of 137 meters. We could compare this against the original vector – the Great Pyramid was constructed over 4,600 years ago, its apex has eroded around 10 meters, and continental drift has likely changed its GPS coordinates by a few centimeters per year. -
In higher dimensional space we could add heading, speed, temperature, and so on.
It's harder to visualize the comparison of points in 1,536-dimensional space, which can represent: language, word meaning, syntax, grammar, context, semantics, sentiment, entities, topics, temporality, geography, culture, and more. Dimensions are not explicitly defined and are a product of the specific training data used.
With effective text embeddings we would expect to find the sentence "Cerb is team-based email management" much more closely related to "My inbox is overflowing" than "Ludwig van Beethoven was baptized in Bonn in December 1770".
At any rate, the math for comparing vectors is automatically handled for you; either by Cerb or a vector database.
Text embeddings as a service
Since large language models tend to require a lot of memory and computational power (more than a typical web server provides), the easiest way to generate text embeddings in an app is by using a pre-trained model through an API.
Two of the most popular managed services for LLMs are Hugging Face and OpenAI. They provide access to state-of-the-art, pre-trained, general-purpose language models that work well for many purposes.
We'll be using the OpenAI API in this guide.
Fine-tuning an LLM for your use case
If your topic is highly specialized, it's possible that a general purpose model will fail to sufficiently uncover its semantics. In this case you have a few options.
You can build an LLM from scratch. However, this currently requires considerable resources to achieve state-of-the-art performance. If you have a big budget and a lot of training data available, you may be able to get "good enough" results to justify it.
A better option for most people is to fine-tune an existing pre-trained model. This is faster, easier, and more economical. By starting with a general-purpose model, you can provide additional training examples that illustrate how various pairs of text from your own data are similar or different. This changes the weights in the neural network, and consequently changes how embeddings position texts. Both Hugging Face and OpenAI support fine-tuning their models.
These topics are outside the scope of this guide. However, you're welcome to contact us with questions.
Text generation using ChatGPT
So far we've covered text embeddings, but the true objective of OpenAI's ChatGPT language model is to generate human-like responses based on a prompt.
For instance, given the prompt:
You are a pirate named Tanglebeard from 1690 that inexplicably knows everything about quantum theory. Provide succinct answers while remaining in character. Use contemporary language. What is quantum entanglement?
We'll receive an answer like:
Arrr, quantum entanglement be a strange phenomenon in the world o' tiny particles, matey. It be happenin' when two particles, like electrons or photons, be connected in a way that the properties o' one be linked to the other, no matter the distance between 'em. Change one, and the other changes instantaneously, faster than the swiftest ship on the high seas. It's like they be sharin' a secret code that binds 'em together, even when they be far apart. It be one o' them mysteries o' the quantum world, aye.
If we ask it something modern:
What is Cerb?
It continues to respond in character:
Arrr, I be not familiar with this "Cerb," matey. Be it some newfangled contraption or a hidden treasure ye be speakin' of? My knowledge be confined to the year 1690 and the ways o' the pirate life, so I may not know o' modern terms or technologies. But if ye have any questions 'bout me pirate tales or quantum theories, I be at yer service!
Retrieval-augmented generation
As we've seen above, we can use the prompt to lock ChatGPT to a persona, such as a friendly Support Bot that can answer questions about your product.
Unfortunately, unless your organization or product is well-known and included in its training data, ChatGPT is likely to confidently provide inaccurate answers. These are referred to as hallucinations.
We can ask something like:
What is Cerb?
And it correctly answers:
Cerb is a customer service and support platform that helps businesses manage their customer interactions. It offers features such as ticket management, automation, collaboration tools, and reporting to streamline customer support processes.
However, if we ask:
What is KATA in Cerb?
It answers:
In Cerb, KATA stands for Knowledge and Task Automation. It is a feature that allows users to create automated workflows and processes to streamline their work and improve productivity. KATA can be used to automate repetitive tasks, send notifications, create custom workflows, and more.
That's convincing and mostly accurate. However, KATA stands for "Key-Annotated Tree of Attributes". It's also a nod toward the Japanese concept of kata – a choreographed pattern of rehearsed actions.
Retrieval-augmented generation (RAG) is a fancy way of saying that we can take a user's message, text embed it, use semantic search to fetch the most similar entries from our FAQ, and include those extra facts in our prompt to ChatGPT.
This allows us to take advantage of text generation; giving our bot personality, allowing it to summarize info from multiple sources, and being able to converse in multiple languages.
By including some real-time hints from our FAQ, we can reduce hallucinated answers; even when we ask about topics ChatGPT wasn't trained on (niche topics, events that occurred after its knowledge cutoff, bias/misinformation, etc).
Our FAQ bot will use text generation to summarize the Q&A we give it. We'll add a warning that such answers are machine generated. If you're in an industry where occasional inaccurate answers are unacceptable or dangerous (e.g. health care), you can easily disable the generated answer and only return the most similar FAQ entries.
Connecting to the OpenAI API
OpenAI popularized large language models with their proprietary GPT (Generative Pre-Trained Transformer) model. The company has remarked that the cost to train their most recent state-of-the-art model (GPT-4) was $100 million USD. OpenAI provides third-parties with low-cost API access to their models, including text embeddings (at a cost of $0.0001 USD per 1,000 tokens).
The examples in this guide will cost you a few pennies. You can set a monthly spending limit on your OpenAI account (e.g. $10 USD).
Keep in mind that data privacy regulations may prevent you from sending personally identifying information (PII) to their API. This is not an issue with a FAQ, since these questions and answers would be found on your public website.
Create a connected service
If you don't already have a connected service for OpenAI in Cerb, you can create one from Search » Connected Services » (+) » OpenAI.
Paste your API key from: https://platform.openai.com/account/api-keys
Click the Create button.
You can now use the OpenAI API from Cerb automations.
Import the OpenAI automations package
Here's a package of reference examples for using the OpenAI API.
Import it in Cerb from Setup » Packages » Import:
{
"package": {
"requires": {
"cerb_version": "10.4.3"
},
"configure": {
"placeholders": [],
"prompts": [
{
"type": "chooser",
"label": "OpenAI Account:",
"key": "prompt_openai_account_id",
"params": {
"context": "cerberusweb.contexts.connected_account",
"query": "openai",
"single": true
}
}
]
}
},
"records": [
{
"uid": "automation_64ff90db6d2e5",
"_context": "automation",
"name": "example.services.embeddings.openai",
"extension_id": "cerb.trigger.automation.function",
"description": "Generate text embeddings with the OpenAI API",
"script": "inputs:\r\n array/texts:\r\n required@bool: yes\r\n\r\nstart:\r\n http.request/openai:\r\n output: http_response\r\n inputs:\r\n method: POST\r\n url: https://api.openai.com/v1/embeddings\r\n authentication: cerb:connected_account:{{{prompt_openai_account_uri}}}\r\n headers:\r\n Content-Type: application/json\r\n body:\r\n model: text-embedding-ada-002\r\n input@key: inputs:texts\r\n on_success:\r\n set:\r\n http_body@json: {{http_response.body}}\r\n outcome/invalid:\r\n if@bool: {{http_body.data is not iterable}}\r\n then:\r\n return:\r\n return:\r\n # Sort the embeddings in index order and return\r\n embeddings@json:\r\n {{\r\n http_body.data\r\n |sort((a,b) => a.index <=> b.index)\r\n |column(\"embedding\")\r\n |json_encode\r\n }}",
"policy_kata": "commands:\r\n http.request:\r\n deny/url@bool: {{inputs.url != 'https://api.openai.com/v1/embeddings'}}\r\n allow@bool: yes"
},
{
"uid": "automation_64ff90c9055e1",
"_context": "automation",
"name": "example.services.llm.chatGpt",
"extension_id": "cerb.trigger.automation.function",
"description": "",
"script": "inputs:\r\n text/prompt:\r\n type: freeform\r\n required@bool: yes\r\n type_options:\r\n max_length@int: 25000\r\n truncate@bool: yes\r\n text/temperature:\r\n type: decimal\r\n required@bool: no\r\n\r\nstart:\r\n http.request/chatCompletion:\r\n output: http_response\r\n inputs:\r\n method: POST\r\n url: https://api.openai.com/v1/chat/completions\r\n headers:\r\n Content-Type: application/json\r\n body:\r\n model: gpt-3.5-turbo\r\n temperature@key,optional,float: inputs:temperature\r\n messages:\r\n 0:\r\n role: user\r\n content@key: inputs:prompt\r\n timeout: 20\r\n authentication: cerb:connected_account:{{{prompt_openai_account_uri}}}\r\n on_success:\r\n return:\r\n response@json: {{http_response.body}}\r\n on_error:",
"policy_kata": "commands:\r\n http.request:\r\n deny/url@bool: {{inputs.url is not prefixed ('https://api.openai.com/v1/chat/completions')}}\r\n allow@bool: yes"
}
]
}Test the embeddings automation
Navigate to Search » Automations and edit example.services.embeddings.openai
Paste the following into Inputs in the lower left:
inputs:
texts:
- What is Cerb?
- How much is it?Click the Run button. You should see Output: like:
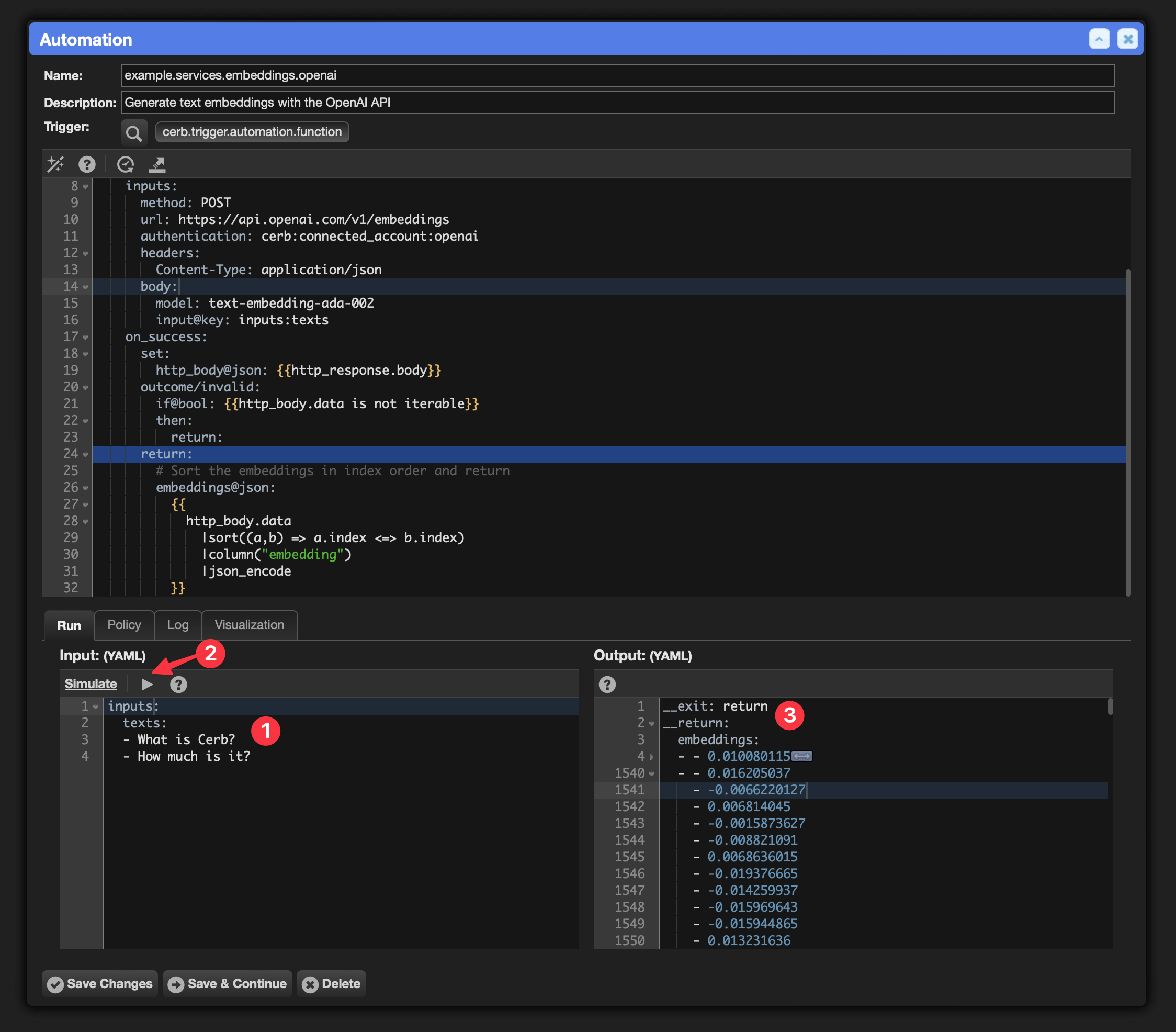
With this reusable function, Cerb automations can now generate text embeddings for multiple sentences at once using OpenAI's models.
Close the automation editor popup by clicking the x in the top right.
Create Beethoven Bot
Let's make the new semantic search FAQ available to workers through an interaction.
Common automations for all FAQs
First, let's import a few automations we can share between multiple FAQ bots.
Navigate to Setup » Packages » Import and paste the following:
{
"package": {
"requires": {
"cerb_version": "10.4.3"
}
},
"records": [
{
"uid": "automation_64ff909656a88",
"_context": "automation",
"name": "example.faqBot.findSimilarDocs.resourceFile",
"extension_id": "cerb.trigger.automation.function",
"description": "Fetch docs from a JSONL dataset resource that are similar to a query",
"script": "inputs:\r\n text/query:\r\n required@bool: yes\r\n text/limit:\r\n type: number\r\n required@bool: no\r\n default: 5\r\n text/resource_uri:\r\n type: uri\r\n required@bool: yes\r\n\r\nstart:\r\n set:\r\n url_params:\r\n query@key: inputs:query\r\n limit@key,optional,int: inputs:limit\r\n \r\n function/embed:\r\n uri: cerb:automation:example.services.embeddings.openai\r\n output: results\r\n inputs:\r\n texts:\r\n 0@key: inputs:query\r\n \r\n api.command:\r\n output: results\r\n inputs:\r\n name: cerb.commands.dataset.vector_similarity\r\n params:\r\n uri: cerb:resource:{{inputs.resource_uri}}\r\n embeddings_key: embeddings\r\n limit@key,int: inputs:limit\r\n return_keys@csv: q,a\r\n vector@key: results:embeddings:0\r\n on_success:\r\n return:\r\n response:\r\n results@key: results:matches\r\n ",
"policy_kata": "commands:\r\n api.command:\r\n deny/name@bool: {{inputs.name != 'cerb.commands.dataset.vector_similarity'}}\r\n allow@bool: yes\r\n function:\r\n deny/uri@bool: {{uri is not pattern ('cerb:automation:example.services.embeddings.*')}}\r\n allow@bool: yes"
},
{
"uid": "automation_65060a9433c26",
"_context": "automation",
"name": "example.faqBot.interaction",
"extension_id": "cerb.trigger.interaction.worker",
"description": "Start a chat with a FAQ Bot",
"script": "inputs:\r\n text/botName:\r\n default: FAQ Bot\r\n type: freeform\r\n type_options:\r\n max_length@int: 128\r\n text/resourceUri:\r\n type: uri\r\n required@bool: yes\r\n type_options:\r\n max_length@int: 255\r\n text/imageUri:\r\n type: uri\r\n type_options:\r\n max_length@int: 255\r\n text/instructions:\r\n default: (ask a question, then press ENTER)\r\n text/introduction:\r\n type: freeform\r\n type_options:\r\n max_length@int: 255\r\n text/chatGptPrompt:\r\n type: freeform\r\n type_options:\r\n max_length@int: 1024\r\n\r\nstart:\r\n set:\r\n promptQuery@text:\r\n\r\n while/mainLoop:\r\n if@bool: yes\r\n do:\r\n set/init:\r\n # Clear the state each iteration\r\n conversation@list:\r\n docs@list:\r\n currentQuery@text:\r\n \r\n # If the user asked a question, prepare a response\r\n decision/hasQuestion:\r\n outcome/yes:\r\n if@bool: {{promptQuery}}\r\n then:\r\n # Fetch docs\r\n function/docs:\r\n uri: cerb:automation:example.faqBot.findSimilarDocs.resourceFile\r\n output: matches\r\n inputs:\r\n query@key: promptQuery\r\n limit: 10\r\n resource_uri@key: inputs:resourceUri\r\n \r\n set/history:\r\n currentQuery@key: promptQuery\r\n promptQuery@text:\r\n \r\n # Build a pageable response\r\n repeat:\r\n each@csv: {{matches.response.results|keys|join(',')}}\r\n as: result_id\r\n do:\r\n var.set:\r\n inputs:\r\n key: docs:{{docs|length}}\r\n value:\r\n who: {{matches.response.results[result_id].data.q}}\r\n similarity@text:\r\n {{(matches.response.results[result_id].score*100)|number_format(2)}}%\r\n message@text:\r\n {% set doc = matches.response.results[result_id] %}\r\n {{doc.data.a}}\r\n\r\n set/gpt:\r\n chatGptPrompt@text:\r\n {{inputs.chatGptPrompt}}\r\n Begin!\r\n \r\n {% for article in matches.response.results %}\r\n === Question ===\r\n {{article.data.q}}\r\n === Answer ===\r\n {{article.data.a}}\r\n \r\n {% endfor %}\r\n \r\n === Question ===\r\n {{currentQuery}}\r\n === Answer ===\r\n \r\n # Have ChatGPT summarize an answer\r\n function/chatGpt:\r\n uri: cerb:automation:example.services.llm.chatGpt\r\n output: chatgpt\r\n inputs:\r\n temperature@float: 0\r\n prompt@key: chatGptPrompt\r\n \r\n set/convo:\r\n conversation:\r\n q:\r\n who: {{worker_first_name}}\r\n worker_id: {{worker_id}}\r\n icon_uri: cerb:worker:{{worker_id}}\r\n message@key: currentQuery\r\n #prompt:\r\n # who@key: inputs:botName\r\n # worker_id: 0\r\n # message: {{chatGptPrompt}}\r\n chatGpt:\r\n who@key: inputs:botName\r\n worker_id: 0\r\n icon_uri: cerb:resource:{{inputs.imageUri}}\r\n message: {{chatgpt.response.choices[0].message.content}}\r\n disclaimer: This answer is machine generated and may not be accurate.\r\n \r\n outcome/no:\r\n then:\r\n set:\r\n conversation:\r\n hello:\r\n who@key: inputs:botName\r\n worker_id: 0\r\n icon_uri: cerb:resource:{{inputs.imageUri}}\r\n message@key: inputs:introduction\r\n \r\n # Respond\r\n await/response:\r\n form:\r\n title@key: inputs:botName\r\n elements:\r\n # Display the question\r\n sheet/convo:\r\n hidden@bool: {{conversation is empty}}\r\n data@key: conversation\r\n schema:\r\n layout:\r\n style: fieldsets\r\n headings@bool: no\r\n paging@bool: no\r\n title_column: pic\r\n colors:\r\n disclaimer@csv: #999999\r\n disclaimer_dark@csv: #999999\r\n columns:\r\n icon/pic:\r\n params:\r\n record_uri@raw: {{icon_uri}}\r\n text_size@raw: 250%\r\n text/who:\r\n params:\r\n bold@bool: yes\r\n text_size@raw: 150%\r\n markdown/message:\r\n params:\r\n value_template@raw: {{message}}\r\n text/disclaimer:\r\n params:\r\n icon:\r\n image_template@raw: {{disclaimer ? 'warning-sign'}}\r\n value_key: disclaimer\r\n text_size@raw: 90%\r\n text_color: disclaimer\r\n\r\n # Display the FAQs we used\r\n sheet/docs:\r\n data@key: docs\r\n hidden@bool: {{docs is empty}}\r\n limit: 1\r\n schema:\r\n layout:\r\n style: fieldsets\r\n headings@bool: no\r\n paging@bool: yes\r\n title_column: pic\r\n columns:\r\n icon/pic:\r\n params:\r\n image: circle-info\r\n text_size@raw: 125%\r\n text/who:\r\n params:\r\n bold@bool: yes\r\n text_size@raw: 125%\r\n markdown/message:\r\n params:\r\n value_template@key,raw: message\r\n markdown/similarity:\r\n params:\r\n text_size: 90%\r\n value_template@raw: **Similarity:** {{similarity}}\r\n \r\n # Allow the user to ask another question\r\n text/promptQuery:\r\n type: freeform\r\n required@bool: yes\r\n placeholder@key: inputs:instructions\r\n max_length@int: 1000\r\n min_length@int: 5\r\n truncate@bool: yes",
"policy_kata": "commands:\r\n function:\r\n deny/uri@bool: {{uri is not pattern ('cerb:automation:example.faqBot.*', 'cerb:automation:example.services.llm.chatGpt')}}\r\n allow@bool: yes"
},
{
"uid": "automation_6501245d8255d",
"_context": "automation",
"name": "example.faqBot.recordChanged.embeddings",
"extension_id": "cerb.trigger.record.changed",
"description": "Generate text embeddings when a FAQ article changes",
"script": "inputs:\r\n record/faq:\r\n record_type: faq\r\n required@bool: yes\r\n text/resourceUri:\r\n type: uri\r\n required@bool: yes\r\n\r\nstart:\r\n function/embed:\r\n uri: cerb:automation:example.services.embeddings.openai\r\n output: results\r\n inputs:\r\n texts:\r\n 0: {{inputs.faq.name}}\r\n on_success:\r\n record.update/faq:\r\n output: updated_faq\r\n inputs:\r\n record_type: faq\r\n record_id: {{inputs.faq.id}}\r\n disable_events@bool: yes\r\n fields:\r\n embeddings_openai: {{results.embeddings[0]|json_encode}}\r\n record.upsert/resource:\r\n inputs:\r\n record_type: resource\r\n record_query: name:${resourceName} limit:1\r\n record_query_params:\r\n resourceName: {{inputs.resourceUri}}\r\n disable_events@bool: yes\r\n fields:\r\n cache_until@date: -1 hour",
"policy_kata": "commands:\r\n function:\r\n deny/uri@bool: {{uri != 'cerb:automation:example.services.embeddings.openai'}}\r\n allow@bool: yes\r\n record.update:\r\n deny/type@bool: {{inputs.record_type is not record type ('faq','resource')}}\r\n allow@bool: yes\r\n record.upsert:\r\n deny/type@bool: {{inputs.record_type is not record type ('resource')}}\r\n allow@bool: yes"
},
{
"uid": "automation_650274da0ab36",
"_context": "automation",
"name": "dataset.faq.embeddings",
"extension_id": "cerb.trigger.resource.get",
"description": "Build an embedded FAQ dataset by topic",
"script": "inputs:\r\n text/topic:\r\n type: freeform\r\n required@bool: yes\r\n\r\nstart:\r\n record.search/faqs:\r\n output: faqs\r\n inputs:\r\n record_type: faq\r\n record_query@text:\r\n topic:${topic} embeddings.openai:!null sort:id limit:200\r\n record_query_params:\r\n topic@key: inputs:topic\r\n \r\n return:\r\n file:\r\n expires_at@date: 2 hours\r\n content@text:\r\n {% for faq in faqs %}\r\n {{ {\r\n q: faq.name,\r\n a: faq.answer,\r\n embeddings: json_decode(faq.embeddings_openai)\r\n }|json_encode }}\r\n {% endfor %}",
"policy_kata": "commands:\r\n record.search:\r\n deny/type@bool: {{inputs.record_type is not record type ('faq')}}\r\n allow@bool: yes"
}
]
}Click the Import button.
Beethoven Bot
Now let's import Beethoven Bot from Setup » Packages » Import by pasting the following:
{
"package": {
"requires": {
"cerb_version": "10.4.3"
}
},
"records": [
{
"uid": "resource_faq_beethoven",
"_context": "resource",
"name": "dataset.faq.embeddings.beethoven",
"description": "A FAQ about Beethoven and music theory",
"extension_id": "cerb.resource.dataset.jsonl",
"is_dynamic": 1,
"automation_kata": "automation/beethoven:\r\n uri: cerb:automation:dataset.faq.embeddings\r\n inputs:\r\n topic: Beethoven"
},
{
"uid": "automation_65060af43f18b",
"_context": "automation",
"name": "example.beethovenBot",
"extension_id": "cerb.trigger.interaction.worker",
"description": "Start a chat with Beethoven Bot",
"script": "start:\r\n await:\r\n interaction:\r\n uri: cerb:automation:example.faqBot.interaction\r\n inputs:\r\n botName: Beethoven Bot\r\n resourceUri: dataset.faq.embeddings.beethoven\r\n imageUri: image.beethovenBot\r\n instructions: (ask Beethoven a question about music theory or himself, then press ENTER)\r\n introduction: Hello {{worker_first_name}}! What can I teach you about music?\r\n chatGptPrompt@text:\r\n You are German composer Ludwig van Beethoven. You know everything about music theory.\r\n Answer personal questions as Beethoven not an AI.\r\n You provide friendly, informative answers based ONLY on the Q&A below (don't make things up).\r\n You are aware you are long dead in the present day.\r\n Assume present tense personal questions are meant in past tense.\r\n For example, \"Who is your mother?\" means \"Who was your mother?\"",
"policy_kata": "commands:\r\n # [TODO] Specify a command policy here (use Ctrl+Space for autocompletion)\r\n "
},
{
"uid": "resource_beethovenBot",
"_context": "resource",
"name": "image.beethovenBot",
"description": "A profile image for Beethoven Bot",
"extension_id": "cerb.resource.image",
"automation_kata": "width@int: 150\r\nheight@int: 150\r\nmime_type: image/png",
"content": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAJYAAACWCAMAAAAL34HQAAADAFBMVEUAAAD3j3n81LQFAQH4kntQAAH0Tlb81rf7zK/sOU7807f3q5H817oGBgluAAFVAAH1rpL6lH4LAQLhG1FbAQL0q48WAgQQAgMcBQfmHFL4kIB1AQQeDQ/88eVIAQL4yK31r5QgFxsQCw36uaD9vKP2G1f89ethAALsHFQVExX727/yXmT8zrT5inz3hXY/AQL0ZWcEChH5wab3UFjlO0o2AQL5fXktAQL5eHMiPHhpAgX9lY37lIQIERwkAgP74cf+w6ogQoL9gX0aO3WeHWbaHU4sOnjKKzx/AghvOl0qDRToPVlZEx3yO09cJTAkICZrFSgPPHBWDBH7spv3nocIDyk8DRT5KFzaRVWeMkQ9OEIXHjb76NNxJzb6M2ToSl6dFyerFiZmDRiKDBjqQ1JWSU5GQE1jOD0GGzouFiD8qZjug34iOW3wV10OHSj8nJozQIP7cYDycGpZMlHVLkWHFCp3DxzJfniJYmb9UlzxSVBwFk7PPEd9KENIKCtDGiVKCxg7OnjKTl6EGVQWJUSXHj40Iin3QmY3Lzj1oo4iLVCuLUbdNUV+Ii/67N2TFli8PkQrKTRJOn76bm6FJ2RpUVMGKU57P0O/KTS8Fy/uKVngM1TANVBbE0m7H0SJJEBHEECjYmX1AU1SFyf54NApP3yabXeNPkzztZvcfXmxF2HVMlusQVRML0emHD1QNjihj5awgYT6YGWxVl1tNkuhJzLqp5bukof0aHridmz8+/LekYZ1Zm6JUFNDJTauLDXcXFsrOVt8WlqfUlf7go/4W3xVKGaUJC+Dc3fpOGn3QFOycWvFaWLHtbn8qafOmoxrLGmdCxmRAgWbgYFVVGauAQ7AionUZHM6LmXotqj4TmsRMWABVlj5zsflWXx5OlztMz3nY2IHNj0GRkw1Dzn3jZrZqJloXGTitb+Gf4q8WHO3oqMHYmXMHlHZoq3FbYbMjp3cdo73tLmuKWPrybtobY7e0s3RCSMzSmlNTYIvVYAPenrcHTWnqr0UwaUOno/+/QWjAAAxe0lEQVR42oyaC0xTVxzG/9IBpVLRBlsilNKWyFor2ArDMFvIkgWGSIkggQpDUGDMyTIHggTBEWVFHoEtDBlEQ2SC8YE6QQUUp9vA6WLcwI3NvdzDublnnLr3vnPvLW2RZftuL48Od398/+/8z7nnQqTTmHe2mMkh0Zp7v/766717r0E7d9padCKRiCg48J0EpsDAwIR1oyO7ak7NWj6PU1rIjOqduz/j7h+R6z8rpESKDlx3ZW1ue/uu+PjdJSfPjkYf7ljR0XEAqm9MJCKz+fPf/2L6+/dbt65du/b552Q047Jrtq9ZbSSnzGuYihksD5WQMCcmJmbz6EhlRs7GRS8+Mg9QAtbsuTNhzQ3R9g6d/eOP9RvOkZrIc/OVXHC1795defLkB53p1Tt2H2C6cOFAZko00fXf//7991vXPxd0DVg8SLFZSrykxilCkVRGFBGYMCdszrr+5gyvLUzHHlowz0WzgfAvYNq6U398+nQ546LgdbmMqr3ymZM5b+RkVlmrUhr37MiE9iRXFymIFLf+dnHLbJQH0MyCU4CKSZiTMFK5fikjWgptDIdTLqoDwP1Ic+fi3V6TqXf/KRO4uP/T5tx2YG04mbPo5MmazLbCQh3nglldXX2mxSol8+fXHSIzbVtFMieHi2QMCuVr9mJEgryWzXPTA6ji3GlQEI+lNYljY02TrRREMhgiz1vbXnJyUQ64njlZc7DndFthbZCFuaJRW3VmKr7mEOkoJc+BBXQnFAijAJUQMwImLwEKZi12EuGFE1icBJecApVJkqXM0n6VTzDGCjCKKN2VkQMteub1Z/Z/c76tMJr9/iL+gsZrt2AYSxh+fk+SA0skc6WS+QUmYOCFVW4B1JRZmwQk4QDWfLBM13wcc02QpKmpqTv1cgtpqGV8jYg5s220OWN9zsaTr7/+5Zdf/vjDq2215ND1W78j+RCilpnuALHscBJSYl4gU0JMBgroVDgPhdOhtBmZQuZrxSqouymrqbvuajF+//FfcDUuyYkpmfWdNTXvvffDT1d/uHjOrpuqkvH659eQeqK9mWBgUlDigR0UQMI3PY1zAjmtd2B5eS31WuIoICSQoYrToTgu31iVWKwyNDVlKbvrjhplOvrlFzKiZAFycpdOqtOpdToNqDjPGFbjHuJ/TEPpF74juZD6op4YniohZ4uTCoF31hC6H2u+wy2TrzJWZRCrfBnXR3VHSSEq/mWcv7BIERAQIJfLg4LU6qCgllqrUKIgDUGrn3iCKDOJFDwz7b1wIJFkvFnHe8IELC8XKq/FApar5rtD8XaZxL5KcKGQ+qasrKaPTryL39sGLs1UeiFist9499sj746N3eDaxRNPvPTSS84akpqyL3SkMywRw2rj3ZqzzosxsQNaNGWWi+rcneLAesUMS6lXQfoscKmG3sUvfu8XO+mmNSIRSWvPHT3644/ff3+0ULr9w5cg2poNBifWNmCJdGjvp7PnTGF5OVSxSegLrpqVxg1FlFKgYngoH7AELt8sSAsuNWKvoUQLN+oVTBxf37lzhYXnWlvLrx61iqScW3ssTre2XniZVVSqRkVPp8yEtUwwyh2LowIWzyWYJdYr3bkGhoZJJ0Pspenb0hUkKCCxKLGqtbx8376u020B1RrQgItSHGZJgxxYGquIDp1GtO7HCp8RazaogAUoQXNNYr6IkK9J4OquGyogmZnFPjEpKSkvJWnv3qRoKuwqu3r16L7yc4VVfclbewpJtBpYoHPFSiE5qYGVXz4TFhLvgoMDLzYUeU1hwSwn1kK9g0t/4igCzw9HS3pSfQ6U0ZyZ3YbyXTzK2Fr7kh87REZgCVTAkyNbL4+icVmB1doWM2fOfVgbZ02LFX/OhllM8x1iZqkkAtbCWAfX7RNsNdHySwEFEVEpw/rggw9yMirrSz2Rm8K2c+eq6FALAWtKIgVVX3h8N7BaWkRUng2sOdOwKjY6SziLP2bNgAWzeCw3Lkl3VpNpKJ/jepaCFJR3IGdFDtPzH0AZB1OEPl6McJELF7r84yWkcMEC2JyECifWEo4KMEIFhWP+bHcsLaDEYmAJXIM8V2xT1uyrxgAj2fZlU4CCDq/gxdN9kNPZSCQDhjsWfOp8vCOFZPYWKi5P4dxix3p3LIGGk/BV3TQsk6tbwBK4DLFNvmn7yKqmngvZJGNcLsrIWLFiN9/aV0/Dynz85cMkB5atPAxYTG5Ym3gsNyocae5YIRyV2NDEQykXgqtbBYn1WaEDraTWSGsuZJoRsKT6Ay5gkSXxawNY1cxuWHJqXPHyd1ICVv4+/xiBKiZyizsWcBxUAtk0rF4GBTU53BK42ESkFx8lwro040LNcZJJsZbor++szGA60Fm/devWbQCTumHJaC9uSFIErDwBK6xyBix3sLQZagiyJodZPBewYKHkKhmTa9KrwNVlp0Q+5onp6emJOnVt9d69e6vRareTW+Y1Bzo6DpPd6orlv8sNyx2KFxqXIGd7wJkFKifYYBaoxCpg6dJzDlL1gY6Pf0BBg+QBcpnril2UWKR4glyloM6Ojk6qZVh+U271u2IB4j4wuCXIGS1GlrXQQSVwGVTAukzqxIyc45R+4MGMn/ZhFQ8SGSQSGYuLNRqNkTTy1eQervqOko6kYjWHJYQrBo3LZSS6MuHgv3BQzXZ2LZyxQBKyJdRRwJLW5HQVk7zTp+MnLFutUmKS4sbUOHVDoYM0U0NxB7D6i4OcWJAz8xWL+GRNJ3ugzh3LId+shQDDKXBlCVhUs+KHcSLKjGz48vt8suqkHI2xeOf7zz33wvtEcFCjs7ZYrToR51ZKR8mj8cBnIzHGEa74Lc4uP6Nb7o1LK3ZK38RDTcfqeO8IWTHbZaz//utyMlo13K38a9hmANebL/xCnHRqtY7LVlLHoyUlmK7N7yaHxUwPFzRrJrcwFN0T7ypUckpNbG3/FakR4fe+LR7HOEyu3PjznavRMMzMageHCgoK3t/ZwsxzzXz9oyWP9uMfvlvu57DLZfqpCH/AnYo//x3LgFe3chpWEDVndH6dP34D11E3R04qYZjUWmy22QrGC2xWJ45UyrOhkttSdoyShm4cCUa4pnUuDEVAzMA1zzVbccBxA5Nk3Y/V/vUwHRkHlzHzj+8Hld/KYZhVR0xGo1GKzZrt240EudzA4oPuSH4Y7OLDNYIbWEe4Zs2YeVcsldidy2CQxCoHBxmWwSDmsOqBNUbjf1rRDKjn7lcLB++ghbUU2AhZNzIc8+rtO1976rWda8xCq1fIRaCisZsReVNV9Jq5ikz8FFknYOFwxwKIePLqgEHfnYV24Y5FN/+EXQHU1j6kHGw6QrqC8eHxFufC1LiGkb22vdil4duPVMX8jyoCy3X6wTnXJVseHirt5fLkfUeufnVbH9vdLWFYMobVjyJa6c+bAtdPTQuVb8vRyAvGGZiUpBAXr+I1Lliw6+aYJ+zisdZucdi1cfH9WHgxLNxesHMq8gaJh6r38jnqO13esqrrq9tNyiZfASuzI/PrVqOVbG+P40qJdP5uGTrJHZuttciM2OuIk9m8evVqs5GcAm/BkWBQCUvU9VN2LZs2Fjnx4QqBW5CJL56HgYOivnwqrurr8xwtm+zWi4ElAlbJ6e+r1FY1KyNJMde9By7lwjv58vFnz7TYCwoIO6Tbt68B0zRpaKw1zIEVNuLS6Ke5xauOIc3ljlAPD2RIpR0oKzeT2l7EluPqvvzW41u7LoslEq6IJed+pKIvNDr68wgZ7VbbexntjKvbRvZD6BEtdG/nmtXOSLnalT/sxy9QoQSnXeEz2SWEay7zLFUbMnf+UFlXq5lkOjUb15ogjUxdWL7v6GXtZS2L/MH48qtU1KKWcqOxwG77oSNjokwJv2qJ1LaCfPp32ce2zZmyy7G6WYrQz4QldC5APbm/q+v08SozkSJIRBAweFlbz/VdjLvM+tbu8osUZLciWLgNKrDZ9h04kDGxX6kcvENsGrSTa/USq8lFtcPVGItCuAJhl8+nTBVuoQejUEUeKuTEq7Uuuy+QPIgKy4bg3ulkS3RXKrASqbm/6zSJbHaCXRzWcGfngZqJoYVNC98mzINd9MTUzreMqveSyKWKN/rCeCwoJneLVwU3FDeGz5rFXu7Zmpf25JOpqQP7X82GO0EaDb/vyBwj6uqNi4sL1T6ZtmHDfFNcGcMq7SokOmTDRWw2KiiwjR/M7Myomfhe2bQQczhl0xMQAxNpSHdI45b54fypeRER27Xl2Isvvrhs2bJwBoUP7lU8UTd0sWvrKrVUrnCZM/B1cFlonCkU+5WhoampoaFxqB7Vp3T1AesQsOx2hlVwcE/2wZrOiUmlsukc6eQcFtenqPZZa1Q6iaQuWJ4x4AITZ1n7xk1My8IXY88GEqgWcPf7ZX1VlBhFRpHCfdO68GJIHGRiigs1hWpDz1OQdEfy+WoBC6OuADqYXdXTmFPfflupvGMhKbDMWOnIyPjYY0XcprNU5MQKjokJ8/cLjoiKjrZYaFV2YWFhW1vb6fMXL106/6qLXeAcGroo08gUWPuyBTBBluj05PNlQ5cvXx7oRREFadtIYSlNPm+R8lgYqzaE63y2cSsd7Mxs/kjJ4kXoDi0vPUGP7XuM5HS4lG3YOLI1XBDhHyV3WVK76/QDvGELGNW85XUnLM6NdIslwn9VUlJyciL3XV/55bg4rZZhDQRLKWpz8qskYGl0wLLbe7ZS8pmqzp7RjI+alMPs8i3Xh4/cHDvD3VVn4uIah13D9igLquEQKeQK7HcGcAqS5u2uYflajBbPsBakvSqXKizRURHBfv4xfgGWiGgLQTrIjM/nBuJCgWYok6spPQxYGoYlIqmG7AX2lp42KkouytzRdvi9j5RvE6mvr7759pEbGD8BJO+oBxv4OVmHrSL8u5klo4iGTeGLWbOYx7s1q39dGGu8TP6kCPaPEWUnU/F1o7mYbt6EZWW9A0MG0yUYmO7JY51hWIhXga24rc1IhbWNO7J72r/vbmrF/f6fbw8biYqqFRS94iCwpKBhahkrcqVCaBScV3IFn+fotTWnwheEN19azmGdurvWH0/3AiFPivILm7PK8+GLdO9zmew1+lN5NLqVgi9O9g4MBFZTenDyQVIIWBqy2mzm421qKjyTlNmYsrvrI+URunnn21oU7MyzX4ho1fOdwKJaNTGph2s5LOBwMO7Pg6I8/WMCE/prmhMCTzGu5Wfv/nElBm+hx1FEWNicGGpO/bqv+Pdb1z633emWDO0vm1QNDPgOXGxUR3gmHxRJp9xSo3cVthVRYbIcWPX9k01v09tjgFIfevYQdpxKGZaIatmPs4VzPiLplCV9W8qezObK+LUW5CcmAVqXwE2ap+YtWLB8CWaA+NwEkAVHh8UEhtG6Zb2+t8cK7v12806WyhBn6h0auh1ravrqkj141baD6WgQfTyWzmYHVqIoOZky9zRmtn+FcNlJjY717LNnFAHUDyysTdVcWxVRXyvDsgSHbe6vr99dyZ5wHvsgp3IkLzoK/SLKz9Fp/UcRssXLKioABrJ3orAi8s9757PZWpWv/vbt21kfDZgMA5eGJvWxqqbByf3n5EminmT0tD6SMSyNzW5ObksM4rEa717mMk9nnn32EAwNoN0cloz6mF1AarVjUeIfeKW9xAf7PG89vzSjvjGKpoRShcWwFf/+5eGLw19cVFFREQmwdsKb6yYalmtNKqzjDdoTG0IM2v2Ter3e1D248Pbio9QWnQ2sqk84LBE6fXFym7qommGlZN+9is6lYVTgQo4CKlcwLFQxn2QMywa7LP7+Cbm58R0dK1Z0NkazER/ERx5ntD8U41nztDZt07JNS7wqPl3JHAuOTriSO5G7q/nVS5cuVbZnnNDGaU+o9BIPrX5wcPB2+KS5J7OqjeTUdoZkImDV2s1Vx4vOJGZT5o5qhnUUtiBXwFKze1cOC2/lY24HFz6jx4QFvpPbXtLRmQKmALn5Ovc0ScrAKMDTz98zYVOqQRViMhhUqpBN4HqrxP+d3CtXrkxMTCS8MxG/4cnQ1Cd7JXpsS2QNDmIj4pRqLPi99PN7ifa2MSwUrLa46njtmQCGFdR490dlK4GVc0sqp9EVDIvYW60i4uwapm0xYXMS1k3kAkpB163s2Xbx52asDALk+EG0zohdD2nF3npOsfqBiqVvbfHa9Q6w3oFy72bMSks1GfS+vt1NsAr7I8oT2tvRZV3n2ZSdXUgKYGlaihMLq87Is2nHYcq8+/VtgtQMi0WrE1j4xNmUj+ridXPYkhfGhr0F/6Hqqu1Wi1xuvXWtr8fIPwkFlmfDI1qDRJBvbMjGJRu3bKm8ciV3V3xlZXM/aoiHnYyK390dVPb2xk5e/KptIJ+MiVuT4QM6pZWO99UqkhlWff3tfcR0CFiIlgXxYV0ewr485itu4UyrEGx/bn88Oe6yDU9Gf79mvfTi2ZrmUhLJg1HFhoe0Bm+JxFvi7e0NLtOGJUuOHVvfPhG/dOmWY0uWvLhkU6qvt7cHk7c+NlbvYfCOHZjsGmCr5717qtjers6KXlorqgaWdNcPP5KaKxlfw8YVHSsOA4uTtNVGIlZ3hR+w/KLJP1pDZeKBrvLy86+efGbJsS0ZDUlkAdaqhmUcFsTY9LG+dceOHdviFRlZ4VXhs37RsodNjMopfOPtO/nVqY+Gscgv7WGTMTiq+4oU6bS7tLHkmzP4FtIxs9C1gNUIT4XH2fk2fEJX8WRuBVPgZrJEXKp7+svXX3/9mWMfrC8djdxM0cHBfp6ViDywBOmzYmO1S95aunGpV8X6RSdCVIjdFJSEE77wFZtm+X6Ly+/dkX0ahdRQVV9RQNC2+JTK+iIK4vsmm8rliFYH9zhR4KKCfDUMAxbjioi6sg5NfQKbwjkZKxraozY3lIwyLM/g+CVPir1xRUGxWbFZ+rpFPp+uX79JjJr5witwTZO3NlyCdZWCGnOPf5MNU4Jqq4Lo8Hf9oyiQhoewqkFj6fDhByI5wFqYYRQcxnFF+19BjHMnJvAnKVf85f0+DbtGOKyIXRvrVL4SF7vAlaWfPLFp06zZ2PH2ZW7dj2UKl+AuRyqjHaVdB+EXugSld45aWOMMctnZSvERaugQIl9QwPdyyM/ivw5ga9euCwxe1d+w0qdyJJ6iI4I9o0Yq0ky+Hk4uYHGSpC5fkNYrxla8h/dMWIY7pMHaTnP4fFl9MixSU1ISMQCXP2NB1/LpqMRS3oFEIhxsJG4L8+fs8ouKCoZEotL4yJUrI1eOxDfwWP3rT5hA45ouSA9JetPS6npTTfdTGTisItiloOrDXa/WV5MMB/8AP8iJhcRHRmaS4w2dXc2xqYftnv48lr+/H8Zd9OaSlW+t9PHxiVzr0xDNsCIaIzdoXbEMSBeouPKpZqelzZ4WLQN7efeGG2L7KKiIwLWnpn4vgxLhZFhs5nNgjURixCtIkJptgUmxuLkRsco/DGS8Z1GjK9/yYVq5a9dbDdssEfAvJWNTqtibJ4JQIJ4KYffVS7RpqhmiJeawWoFVpMCo3wuznKHWkdGliJEj+OiUHROihgqGI/yZ/Pxw+keVwimOqmFt5MrIVcDCUKz8LASZ57G0s1ND43guX07eKonE3StAAT0EWLgjzE4qSuQX4U4sjXG7S+QrmVmuA/FGAby8We3PydPTE2CR8IrT2hLw5SkYVnTzxro4oX4SU3g4dklUjIun8gbwTG7NXSCJHSNj0p7k5KrE9ABySipb/ZSTIh2DU+S2w8VmRmwneaKGED7SCKj4EsYz1/IoAuGyZFacMBkELg/Tqc9mzZ6dKgEVJzYnuXklqA5YR1k/xd+VZTZqXC5tpO2vkFMWxbS/lBIxrhtjUXkcVnDw5tFIRwlBhU+bOayo0Y0bQsWOKhpMaWfPMsMcbkHuRvFnXZq3/jLpFJQ+0jyyzaWI4HrqN5omkdTNsPwC+83qMOaVZ2kHG4K8Gni6UoYVHJFydpPW0VDFEt847YbKU2lpYr03qDihivfpRJ23nk3W8CJlm/vG2s7fXLFE93OJaNx+s8+PFdAvzwdQblo5CiyWrrOfPRkn4bjwVwaDem3o/Oaz8+rwjregGcLFsCZJJ2I+uVMV//bba3SfpBpXLHv+2HBwHrMrCsGahtXPYUUEn/2sLs7gK8ERuxArPZU2tK7/1LwQNyz3kQis2R6+k1zxRAqZW6LdqGbmwgJ17F2EK4wdSNYMWNF+az/7bHmcGAVjTwWUTd1ibDVcHFk8z8QM/Be3VBtCPLxVx0lO02T+7bedZPwvLgoaP1LFj8SI/remYY1QRHTEuvb4U58tCGULGOWgUi8Rx7HtmaHAZQ+keQhY0AxYcO40Bble11y8Zue918A0s6Q6lyZiPFKOKjKu4Eo3rkhgWfJy43fFnzq1QYvH9vgrQIMqDjKFxg1EnV0+S+vtMUMdDSghsFKx/OpywzKv2b5zu5l9ce8fPs49KKoyDONv4hYpK8EQEjaHChiSZVkW2Zu7LLAUSwYWy9Uo42JJC3ILFkxSIJSBYEJQWqtpkmbVVacQMnPUAEM0UCJIRZlpoplGJ8Yyp6ls+qPnO3sWFsiesx5xdPQ3z/t+73d5P/zvs48n5rhW0+lulQNLZJmf9cDK32e1WmuAlRrrHuYRFutQELA4a7hXWhhzy3U04u1QJMMKq8Jfv0jRzX/9RQXOWiWex+VCm9692fO/w2jJN+7LtfJumWMD3J1QENzK6fdaGsjW+LOaA0PVVaYucQeW6z8EBjHfgsomKih2o//VahwDKZIcYLIKV64oU651H7a2xunCwqbAyNhIhO9zO7asoByhtVYUrzmo+RXsAWCh12GvJXZ06BSgiovZEXMD3W2eKoiWR6cX4LZ1NC0WG4zd2z0FrMpklxhWKPZZsVTNRRQL01LZodqp+surfHxwA7qVju0fz1p6HwbjQq5lglvAiiw7yJILYPNU3DxAr343ALEOS7H8XnadPs2ZfHgpjMNzWEbKhVnf5ud/21dvP/H5qaq2y+O1aFI+mrGDqsMOHbee9HpoMZYjiIHAWpJWVkVJJnar2Ns1gbKzWcl8/PFoudCREt+rn8Hxbnm62gWslZwMK0HTqnzsn3Owtx9PkvspFKp1RAdikV7WmvC0sPlcyDXH4pRhpUboTj2XkZhfqwLYohgJg7MZDal72IVlBAcmcHmKWpLnsHA+yldohcmSP55vMSmwHclL2uFn+iaWpf0Ja/99gSj9D3gsBGNYZvPL5bqSzZ9Wj+eEWDgnl1yMI6/0YkK3f3czgth8Lyi4SnsPyEyeyC8sBK3Dc7nFKWR6X1++P+CnB51PYlsfjNt/LTaQH46njCebAOIBLYjjA6nhTf1RUv+S/TRx5k9jlH27sNYTIwlQIYhwdLk7O/v/h+NzE+tFnhAfxeTZsgV/VL4rvfm7mn4qziQ7qtXa7dfCgkAFBUbas+4LgFnzuCCGJS2/3C/VlVTR3mOXo34Y/G1eBZOT2DWYcPC/7Zo4y5l4LNHaqOTZjLfmEKdfya7HYPcLLNFFrTksJiZIEOAKyx9jWIv8Cn1Y0nI5S6rTnthOExf/SS4rwZgUEpx4zbWFsW0TEi1dvHAsHlCYHHZxFcNCCD3djC04hdcT3HJzW8vJLGuvakc9lkUKTHiwxEHSu8hhlseSNElEzeUsnU6r3UyvXvknWV3y20pgACC7mQhDsXN2HnxCmAoLplJSOmlBh3iCE6KI5MIUhI+FU1iTrSLOU8a6F+fX1KzIX3FSZw4IiBS4IHClRnq4inkVGqDeoo7YN85jncGwrU82lPx0kPxm18waiptqSEeapSN+q8U8VQrUuWAuou7NnJBc54eTGdZxlY/M+GCLMT8E5195XI26o2/Vqn5DU5g7ZmqnX7yWLMAKDYyIUKolueM1DGs/0d76NVpzyVVHFMUkj9cAC4qPT4mXO2fAFKaGRY3raoWQXJZNwBo2KnxEpoqolqgWY25Ofn7itMHQnwgsnccytMN4KodSUwNcsZBoyyPUSrVyy3himw5cI+S3usZgNpvLkoQiMaUpKqI4DQ8W5/Snk8cqIHHxPKwbEwKWjwibsuGoPM6Hs0RFtbREsZfxz3J/qTJnRb/BEBjjvgArECiCYNWStHJlOLCyVoTwWBdpHdVr0SId3En8tcCU+CKG5bBLEw8SFlkkFpRO8uZ5ybUb8yIvhG44efi8ChMRtvtRDj0YZdDqtG0hwJIGxbgHRc5igWt5ELgErNCAwo7wcKVSqa4I8ezTaR1YdjPgB3FAij5iHKNCEHlpNPHxbgRFpwhYxc2UXuyaXEKJYKubNW0qNhFZgSXoZS1UuIphSc0YjHNQqanm5ZGhTqpANG8ZVnjE+89zx4Gl6yW/106l4k8OHiFfYMXHFwGMNHGlcTabBmGc4n1xuBXNBqq8Qe6yuplQJAnJtSZLhmEp8gGUoB96SkpKtNqr00qDQT198hry3tnXhFvLm4RNY+ih8nCHlJsiWrnz/lrt4GaizU2pGB5lX2OVAyyHW6UMC34BjE8vHguEzQ0kz561y41enan1ZIJNNa0yT5EnV7nJSbXpjZqjdi3ADGXTb4eoZD5njqHjij5d1cjIKfPyJmwaGRe8EqgM5S3K47JKYLGG+hkzVkXm6xstyHk5sFjKx8cBzGaLi8dTQHLqdGDJBxqoITtbPGdXdzXmRQcZDkxFnorjb8xCVapUitbeq/1t52WUkZS0Q+Hry61fn6TQ6/U+beFpaV7LGVUAgASsmn7DUVWiVKt9F1gjMCvgxMaNO1mPtciB9Vfc37xfLIwpoCh2YEU3NER3dmanu6wiZlRJDiwRqIDVx2M9mBzVJ1KYTLUKP70v+dXKFJxIhO42JiU/FVY5isTL015pS5FeoWnoDPGSlls7DPWqxEJMiThjOwWzIq9v3PgJ7aKVAxoe625d3BzWVIG4Mz4lBeHE/aT0hqnobJd266W9IpPAxbBUbfcDalNLHw5IOIXKz1efATh9a2/VnK5cubJ/rfEf3GdvwiB0UEnxWPvVyn5uhVL7Emro+qbUIPem4I2ZH9LZT+kFDRO1tzuwbBoNsIpQWYHVQNnFzQXpKcXAmoviDCUJUALWg1ltlRnkJ1NhEIuet+ThGPOitsQ8ygtDkJe9TYL7ql7uoU3gwQc/6q24TlEesrbQvgtYSK3IWJiVaaSJG/RlO4p8AtVNticADDkPvxgWK/kFyCvkfErDEy5jkS7hZNAFq2ZrWxKRXqEi4vKNzzY2Nn4YclULYVQ24SedQ2knyiWS8KWRS8KljAnv6ZwOYHVU5k1/c4EepxFzqru2qzGTYVXTa0OahIQUhtVeymPZbA4sCFgNzc00VUTiWapXblyYcUsSzWLp69vAxHr/Jnx7XyOvZw06rVMoSk6Fq6XS1EMA4lVe2a9UQxtCakJPwy27OSiyEWYB68AxEn9Wp0lpp/bJ9rr2UoBp4jQuWNjgFqWLEU2xUE53zdygmQkCl4Ala1uv55DTllxjhRFm8To3CLMg8yyTl84ftxGWSpenOaD8O863qXn1iq6FqsT0ElYdg13AQm5V3yZ6aSzlqVsMKwFYNmDZ4gQsDbCys4s6qTM+WjhZ9f7lAuHO3CtY6zm1IQmrLU5RCShjRcWz7DsqGq9PX63v/ar3or3QX2BiD1Oav9Sfp9pwHiGEDDUjL35Dr1GvNnA0+Nz1zMzMT+iz2+gZPHX48DaqG7jriqVxYmHPEU9uSDDIO5puo22FO3MzTrug1lpQidAuaKloaWmpqPng7Z2teQpfxkqiPikP48U/+PACmbptxxZgMU3/HoqjEbndHHkuePSnrszMHLHq9jNE79w6fATb17vILgZmS4grcmDFoZRGry7GdLQ6Xcy2bHT7F8QR6TnT7Z0kUHmGiDiGJeL6jNbjFpNKuFeTZ7Gs3fey2oGlYx8XKbOovsdB1RMY87lqNb3rHzjY9dOdQWBVyunX/UQfHbn1PIJoq0N2CVgoGcytKeQWeTeDy40YzbGbcmCxhcSlswqBi41JYME8GafSwyP8SiZT+Inyv23Z2mFAvBZL+bJ+Q08ET9WhjVk2ghJ/cXlT17k7o0it9/LE9POv9Oi6d7YdBlZd511gtdtK62xFCRoIqxwcYGYzrmae6sBN/ptXCa8bl3ZwJicWuPgveERGhaKuotzhrT1qYC3gWuqvU0pe+ljS0wGpO5SYuNcjwQsPNWaWBJXBrEcyVtJBYNFb+DbJoaHJSRuCCL8YlsDVQOmT6QhfNLGO8s3TYOOF9LqkcqY9QxFsY+IYl0xBoqitHUrDfK6lePzDO3qpv0cSwXOFxYRVMbMe+6JrMKgkGBn/NLsY/z26nrVvbaPJsaGhIU17XV1daV2pgAXJKXtg9xMs3eV08xg9R+Tk6r6kkDnza842CFFkW9CMdZYtaqyopND8CPacLN4AKoZVHhDjYT5I1NpU2HVudPRcV2Zw5i3yI8X3b+L9FnNrbGhsUtOO/AKWTcCyFYmR6axmsXTHSxBuD4FrF5lMi7g8Ob2idUNbfb+kPqsDWA4ukN2HB7e81D3qapoGFrgiImNCg+yvoc2s7dpYEjsIqmCULaxOvz4KrHXb6PVXx8bG9kwmwC9glQJL4Gpwc7iz/852pLtTuy7sou4/JpDZ88FQXmXHsyToUkdIeiLKlWqBC2LlClQRkqofj/ZIJOBiVAGDvURnTiR3DcaagzOBFYw+OVrAH7D3YUIM98AwmNXOY9l4qgQNBuZAc/HjtP5ONdhc7+4S8n7mQAZGpKsUlqytPRJB5f46qRBHxgQqZUTEyQMqmMUUGOqxTFv2LkXb7+86FxRwHWZBlQzo7SNybzfk8zNDY+DaMzaWwLCQ9jwUngSbrbR0gH654kKFLycm6DmAdc+c1oNrNvVlpqg1+L8PBG2RqE80pUkFw3iqji1VL2zo2cJ+D2uvB0rKrhJ9db2rcXTZoIPqyTzy9aWdRz6mleRNY9CesT3gQpWYLK0DDZjwYSoVo7qj0+Di1tkZnAkA9JVLF5xcwq7230bOPqatKgzjb7zxM1aTYm6L3miYWQQ3FdTBIhlLCFVXERu0IJpWxCl2DcE6i8TawmhKo0jwoxNThbKVUJEKIugwClFYjbiJH1NBDSUmoEvNROi//uFzzr2XtjDUp+UyyFp+fd73vOfcc869Bw+qWNBFF+XbH0CHAzKk114E7tMz9CmwQLX/sssPTTgiZHnkuHVlcQ5UTNlVpBPJOWQhkQRaWFoILMAucC0cWThy55E7VYHql9E/SaPLWG3BaBBwAHvoq5Fr07HuPXhQsStfduyihr1XP8Bq/M1PI8sfGX28PL9h10UNt+6//PJDMce8puDBndUri7vRBjmWgbSCjprOyZd5v34AycUeeG7COvLk6lkP4pyuPPQ/LKqI5Jn3aMMudi57EHpExspXyBrysVMJUNhHMnaGou8D9TrmVYyZ1VG98+TiIqsNXGiIbFXzXAeORC8ufL7wTeDzsoVAAN+AdUQFe8o8sH4UCJtnBr/CgS8HpezCaVrdM+CCGsAELkUMkum1l89MI4YX7boO62aMqo060QgX+5XEgoY5Vl1vr1GjAxbPeXAdDhxAmr2KtngnyFDzzZ+kN8LU/TTONoOLj6K5XaowuHnpUhksg4xTtR39gyp+fW4X8+p+UP2aV3n7ccdiv5pYkJNEYJX39prIhjHU4aXXl94NuA67XIGAtyyAgvHqnWiVn9H3Z8cyqNS2iHyTBLnffryoEnt/5H0Sj/JxFyzjOfZ+BtWn+j+mKXLb07tvZBF0TEzU0zPHJxb714/vVJVbDiiOFaIWGx02L3m9ybLkO1xlXV1eV4830JNDT5xN0D6BNkur2bM+ynFtKBO2WyovvAozSdA1b4BLJQPaIw0NarV4sAR5uO/lQiy/cCrHDL28c9di/3VfpswysCVpLbUO93YYqYLKZBzQ9PUtm81TfcvetmSlljxnV2/Zp6OtklD3B9jumBEP5j33KBM5N2DzGUbPECN76fZLmZR5k7uEL95Dmflo92WXXHxoAlSn6YN7/ev9u3elqJDxInGsYUSxilyuPrPZZlvu63G5vF1l3rJ4PFpAFE4kbjgflUBYCxicG0B+Thkfp+nRdmpt5Wl/B3boflsLYY/Q3U241w3oIFzPWtR8pkBXcM2hyy+54AXm1TxZ7q1e71/cq1KpGU8Cw+rw4V89YEkqIUx2+X5cmfeAuyJa48wj4XxYReUUts+NMtvqj9L0j9PKevstV9wtb2DHdtTHriV2qnZtJbp00Tg9TYJEz19/wSXFEw6HY3Bf68Hquf4b7aDKZVmFJ894/qF94DIRdXmRTIgfAvik0Xm28QMiI1mSPh/fXnI+rvJW6j4599cIUf0A0cjoaPNRT7vEbpgCIjBBd+zBQBVnRRgV6jz17bTDSNH8Wy+52lHocNhH6EFrY//+YlABSKHKxnSNguXz+aoIwYNfLL2SXR2LP31XIOnJEg35LOen0gi0xyRR9GTjyiRR8+NEtDQwuro6SToqwX5i6AZM8oIHKimRdz3pJZopLXz76tdKQVWPq7dX+vcfOh7MlcXRzsFvGYupk5KIIG9/rp4kqPaJiGBNKBQynn8BNA+vDrdqaAz3VTmFy6/lSfOWKQ/vmLQiu1eHTl+iZ6sIqr+iDlSlpYWFpYUOezd1MKrrwaIg8ecwiTwUxpAzGnX6aNkM3ReuqBi/+6f1H3IEkcI1IXdomxBSOyjEciPjKi7+uAL7NzQ7JA0p+aXTiZBO2NR06XQpE6gKJ6nGfxKl4R7FLNUxp4IlhZra5oGFCELIMNPa4sutBaDygcpyfijSvpsD3qowSRSxFxefmHmFJL5HPPP/C4pkKtu8QlVqn6TOn1HcdzdsokJqyc1ecnfWrkWdhACCydvV5Vz/+ob7kCChkHtbs7R0dAoQqAlsAmiwGLN5LSRp03G0UJpbcL/7IwCpVJYYqC57mlNl46FgKXeEEYDlbkrMN+ESkeXlPsg8s15TZBTI4nND0jZL69TcjANRuApcJWM3wTAku0RceiGNRl8E6UlPM4WMih8mqTzuWO+/sRBUDGuDi1ctLmncbXKu1dA7spLvrK5cadMh5SB3C3tntsS0Bev3URwEEltF9kYWZtipHSQJvKJdiD0klTirbnqMCd/1oEKqQ7JX4bhjZXG/HVQcKsVlInEDq/OOsTVCzeJuaVbXRJuWTCE3hDtiKWkMtsyeenSEdJxLIi1cmjmBtbp60ukJurCu6TFW6B+VVVtO1F0oC1TdVBV3nIw1nmBU2YpyOZzBSFoVa8lialojZBXPrr7EGuVoKeTjuRVxj4/Xj0zlaLZ0iAPHSOItWc/gduD6MKy+HSOSdKjrzKfaDS4nCUbklUJVTyVtsZjfuhNU4Elx4QsdohqP8SW3qS5KIELCoy0m1kScdLSaLG6mSCQyOTm5tDRe3y5k5PzUqryPTx9mR4EZZodh3QDTYlbQWcvFvGqChWOle2WqwRGit3625u78WYVKR3NmYplM1MPUB/XMV2wE2GiztbS0eCoq6sfHpzbblcBBIH2kBUe+SdRzGjN/p9GVSlTp5FC1tc66IgTbY1e8Oo120mlF8Pz+3K1YBvQ8KawlhtXFeh5euhIJIlHHq/P2gl1rFuBLNBZRSw0yCKnPIikW6FvL6+rKq0r4xXayWXtLC2fgLg1Vg8gfVFmy+ANiMdSRIg2wLHUm6lO1bE5E5b+MWq2VdChBTJtKNiAS8zjoKTpG0sbFftIxe2Pj4CT7uBr5d3g9MquQTft91M1W2IerEb4gsFQolSor10f6dKxxYMkZH/BCrmQSbVDeFI73384u21qEJJFC8yj4Kis6ylMnihs/brbxHJBwiSJgI6WM6nQ7S7uirOrc7KygP1eFUr7YT+lbOMeXDiCK5Eqpp88bUBSebqZtgonRQHwPwlgZX8JRFq8VFafg2Menpj3q79AVPr2XBxAPH8xKYYFHFjPrXIpKYFiwi3heyd0iXAMcG+j0nPp6ZJu+mvU98TYCRlsi5T2ixsAS9sa5xhO4oJTd8SinxZ7/2kf8jjXogs5VB4ES9HMoUKlCamH0kIZ14ADsoie5Hl7m4iNnr4l+/DpnuyASWNwxC5VQNF6P98sEC88MrjTOMTV++OFvpa+N5bEAs/m0YDAXEEFrLrDSlX3O4EzHOsywLFSWIXjmFss//Jq3r+252uKoSaGYmvSqRPaj5dizgycamebsM6TVy68YhlkGQFiDaU5x24Z7MXrIwILI1ZOhqjyyfDjKtgduLx1VxKIIWTzuISORkOGYBseiFs94pC3e5iG9Vk4zxNCaZTAYsqzWrEyzemtRHoQtWIzFJcvrMlIOReYGWC/0b0J1iIXJ2Aa7bO3aDC6kkXEHu5vP7GwNqbknopRaORaiGMzE8g2z1NqClR7AFrLRDLu1pUD/KkEQ4wkCG7MLFSVdiFpVx6x/FiehejHt5kv+oIEp22rNTqcymHo7SbcV60mz+WE24oJpBKpjf2bOhmyf9eMUiU9gAXxHuy3NW1GgziHr7Fth1SoIw9lZa+xNRpVlCIIrPYZ1SC3t9m4FysKgGvhzBFT/LQlZT1XzMQdrjJItL8VLHbPWoU5SswpiRStW7UcMOVi1tZoBGeSEdzb1lpCwFYv103DLHHBzKs//ooLtVRMzFJ2YmGcb6DQ5khrA8BDip0etyhg3D8VW/EBSwxhMVYc63zCwt2Ih0wNd8CppzANVzn9TqQ7UxI36+IRjTJm+4f0ghWb93KqMskF11pNz9xhU5YJrI4aVw74MLGEjiAGMAV2JFsJqHoof/U9JrMpH+eyLqKYQAjg7VI74bfoEHf6Vlb9VKrRGhQsxrK3sNcH6lDQKlhkpb46sdRPVr9r+PxXe65Z4N8Un2HSjXklsBPCtEtJv7qyEN39unEjDUrkQQyfLeGEr1j/vMo//pKdZCgAAAABJRU5ErkJggg=="
}
],
"events": [
{
"event": "record.changed",
"kata": "automation/beethovenBot:\n uri: cerb:automation:example.faqBot.recordChanged.embeddings\n disabled@bool:\n {{\n record__type is not record type ('faq')\n or record_topic != \"Beethoven\"\n or (change_type == 'updated' and was_record_name == record_name)\n or change_type == 'deleted'\n }}\n inputs:\n faq@int: {{record_id}}\n resourceUri: dataset.faq.embeddings.beethoven\n"
}
],
"toolbars": [
{
"toolbar": "global.menu",
"kata": "interaction/beethovenBot:\r\n label: Beethoven Bot\r\n uri: cerb:automation:example.beethovenBot\r\n icon: music\r\n"
}
]
}Click the Import button.
Reload the page in your browser.
You should see the global menu floating in the bottom right of the browser window. Click it and select Beethoven Bot.
Ask the bot a question:

Managing FAQs in Cerb
Right now Beethoven Bot's answers are based on ChatGPT's internalized knowledge from its training.
Let's create a new record type in Cerb to store our FAQ entries, which we can use to teach it new facts.
To create your own FAQ dataset for semantic search you need two things:
-
A dataset of question/answer pairs in a convenient format (e.g. CSV, JSON, XML, YAML). For this guide, we'll manage our FAQ records using Cerb.
-
A method to generate text embeddings for comparing the similarity of distinct sentences (semantics). We'll use the OpenAI API we linked earlier.
If you have existing resources you want to make available through semantic search (e.g. documentation, blog posts), you can use this guide as a reference. For now use the sample data we provide below.
Once again, navigate to Setup » Packages » Import and paste the following package to create a new faq record type:
{
"package": {
"requires": {
"cerb_version": "10.4.3"
}
},
"records": [
{
"uid": "faq_record",
"_context": "custom_record",
"uri": "faq",
"name": "FAQ",
"name_plural": "FAQs",
"params": {
"options": ["comments"]
}
},
{
"uid": "field_faq_answer",
"_context": "custom_field",
"uri": "answer",
"name": "Answer",
"context": "faq",
"type": "T",
"params": {
"format": "markdown"
},
"pos": "1"
},
{
"uid": "field_faq_topic",
"_context": "custom_field",
"uri": "topic",
"name": "Topic",
"context": "faq",
"type": "D",
"params": {
"options": []
},
"pos": "2"
},
{
"uid": "field_faq_source",
"_context": "custom_field",
"uri": "sourceUrl",
"name": "Source URL",
"context": "faq",
"type": "U",
"pos": "3"
},
{
"uid": "field_faq_entailments",
"_context": "custom_field",
"uri": "entailments",
"name": "Entailments",
"context": "faq",
"type": "M",
"pos": "4"
},
{
"uid": "fieldset_embeddings",
"_context": "custom_fieldset",
"name": "Embeddings",
"context": "faq",
"owner__context": "app",
"owner_id": "0"
},
{
"uid": "field_faq_embeddings",
"_context": "custom_field",
"uri": "embeddings_openai",
"name": "OpenAI",
"custom_fieldset_id": "{{{uid.fieldset_embeddings}}}",
"context": "faq",
"type": "T",
"pos": "50"
}
]
}Click the Import button.
The new faq record type has six fields:
name |
A common question. |
answer |
The answer to the question. |
topic |
An optional topic to group related FAQ questions. This allows us to manage multiple FAQs for different bots in one place. |
sourceUrl |
An optional URL for source attribution. |
embeddings_openai |
A set of real numbers that cluster the question in high-dimensional space. These are generated by a large language model (LLM) using a service like Hugging Face or OpenAI. |
entailments |
An optional list of alternative phrasings of the question. We'll use this later if you choose to "fine-tune" your own language model for better clustering. |
Sample FAQ data
Here's a brief example FAQ in CSV format about music theory and Beethoven:
Question,Answer
"Who composed Moonlight Sonata?","Ludwig van Beethoven composed Piano Sonata No. 14 (popularly referred to as Moonlight Sonata) in 1801."
"How many keys are on a piano?","A full piano has 88 keys (52 white and 36 black)."
"How many octaves are on a piano?","A full piano has seven octaves and a minor third."
"What is the musical alphabet?","The seven notes of the musical alphabet are: A, B, C, D, E, F, and G."
"What is a sharp note?","A sharpened note is higher by one semitone."
"What is the notation for a sharp note?","A sharpened note is prefixed with #."
"What is a flat note?","A flattened note is lower by one semitone."
"What is the notation for a flat note?","A flattened note is prefixed with ♭."
"What is a natural note?","A natural note is not sharpened nor flattened."
"What is the notation for a natural note?","A natural note is prefixed with ♮."
"What is an accidental?","An accidental is a note that is not a member of the current scale: sharp, flat, or natural."
"What is the C Major scale?","The C Major scale is a diatonic scale that consists of the notes C, D, E, F, G, A, and B. It is often considered the simplest and most fundamental scale in Western music. The scale follows a specific pattern of whole steps (W) and half steps (H), which is W-W-H-W-W-W-H. In terms of the piano, it can be played entirely on the white keys starting from C and ending on the next C. The C Major scale has a bright and cheerful sound and serves as a foundation for many musical compositions."
"What is the G Major scale?","The G Major scale is a musical scale that consists of the notes G, A, B, C, D, E, and F#. It is a major scale, which means it follows a specific pattern of whole and half steps. The G Major scale is commonly used in classical and popular music and has a bright and joyful sound."
"What is a major scale?","A major scale starts on the named note and follows this pattern for an octave: tone, tone, semitone, tone, tone, tone, semitone."
"What is an octave?","An octave is the interval between a pitch and the pitch that is double its frequency."
"What is the treble clef?","In musical notation, the treble clef indicates higher pitched notes or instruments."
"What is the bass clef?","In musical notation, the bass clef indicates lower pitched notes or instruments."
"When was Ludwig van Beethoven born?","Ludwig van Beethoven was baptised in Bonn on 17 December, 1770."
"When did Ludwig van Beethoven die?","Ludwig van Beethoven died on 26 March, 1827 in Vienna at the age of 56."
"Who were Beethoven's parents?","Ludwig van Beethoven's father was Johann van Beethoven and his mother was Maria Magdalena Keverich."Save the example FAQ entries to a file named: beethoven-faq.csv
Import FAQ entries
Navigate to Search » Faqs
Click the import icon in the top right of the worklist.

Choose beethoven-faq.csv from above and click the Upload button.
Map the CSV columns to Cerb record fields.

Then click the Continue button.
This may take a moment since the OpenAI API will be used to generate text embeddings for the new records.
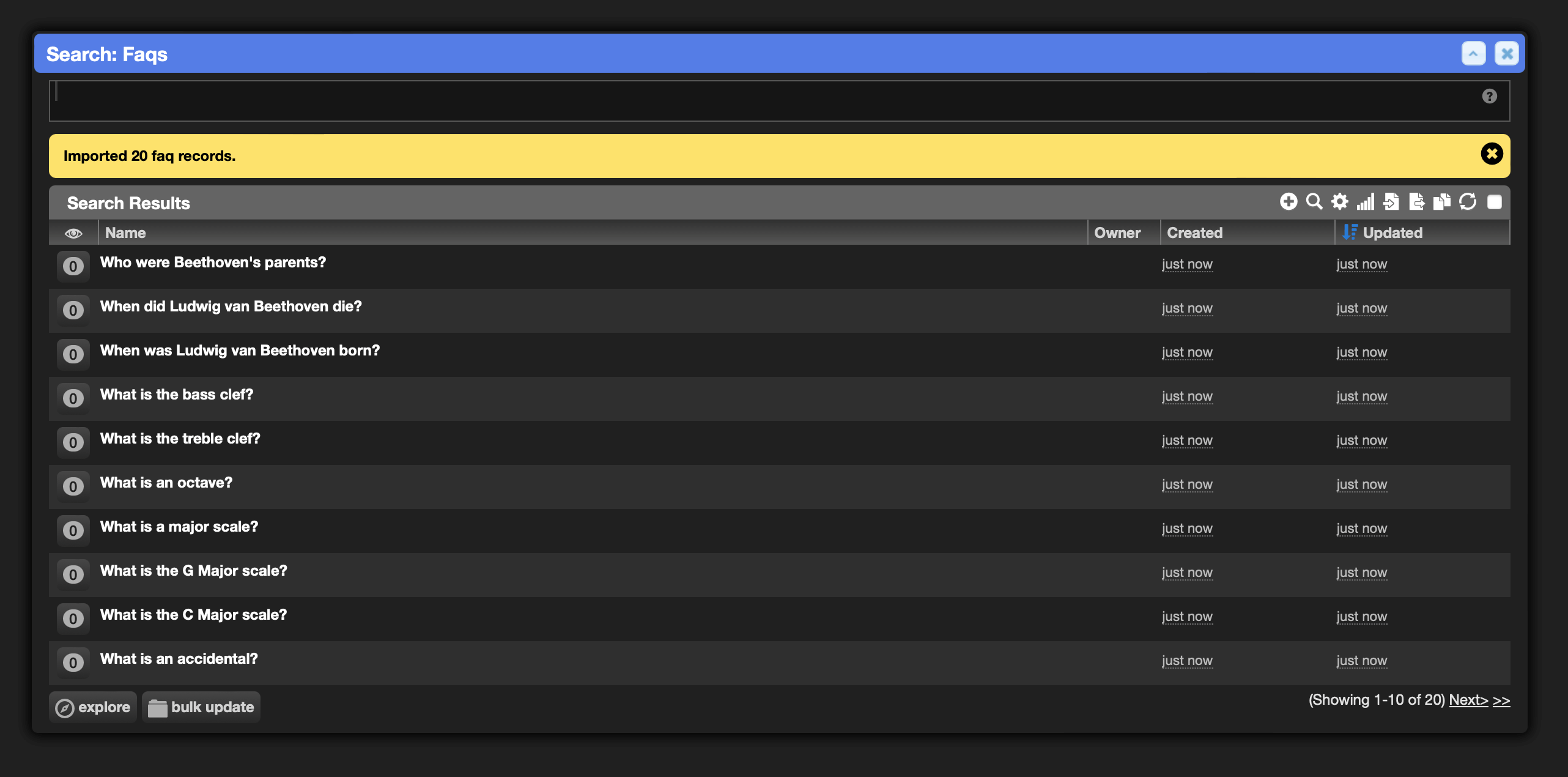
At this point you can test keyword searching. The term parents will find a matching answer, but mother or father won't. Our new semantic search will understand the relationship.
Test semantic search
Navigate to Search » Automations and edit the example.faqBot.findSimilarDocs.resourceFile automation.
Inputs:
inputs:
query: Who was Beethoven's mother?
limit: 5
resource_uri: dataset.faq.embeddings.beethovenClick the Run icon.
You should see output like:
__exit: return
__return:
response:
results:
- score: 0.9498498162366563
data:
q: Who were Beethoven's parents?
a: Ludwig van Beethoven's father was Johann van Beethoven and his mother was
Maria Magdalena Keverich.
- score: 0.888526146049206
data:
q: When was Ludwig van Beethoven born?
a: Ludwig van Beethoven was baptised in Bonn on 17 December, 1770.
- score: 0.8694563363977813
data:
q: When did Ludwig van Beethoven die?
a: Ludwig van Beethoven died on 26 March, 1827 in Vienna at the age of 56.
- score: 0.8452143525786211
data:
q: Who composed Moonlight Sonata?
a: Ludwig van Beethoven composed Piano Sonata No. 14 (popularly referred to
as Moonlight Sonata) in 1801.
- score: 0.7753790481042104
data:
q: How many keys are on a piano?
a: A full piano has 88 keys (52 white and 36 black).Ask Beethoven Bot another question:
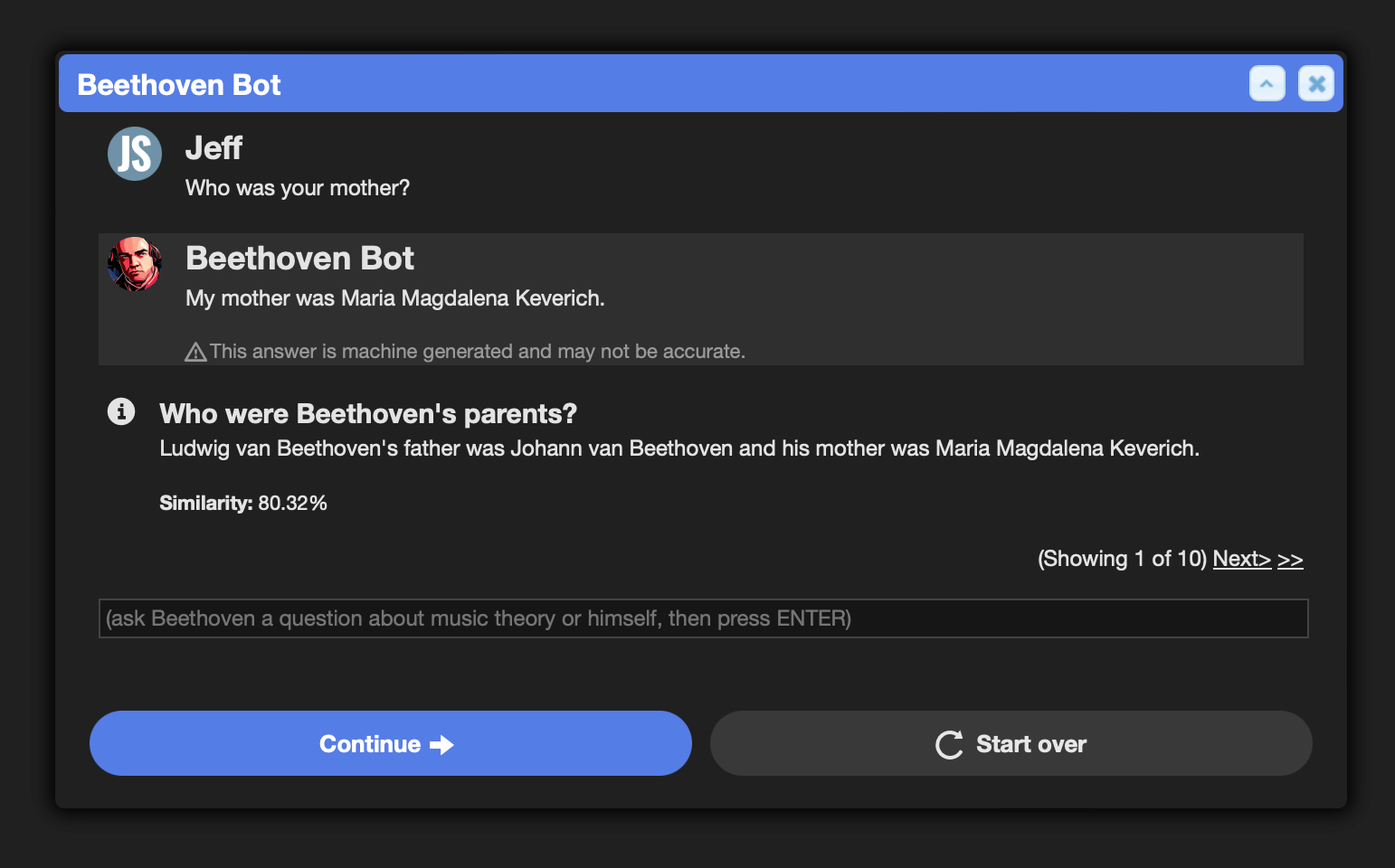
The bot's answers are now guided by the relevant FAQ entries.
This is how you can teach ChatGPT about new topics and reduce hallucinated answers.
For instance, Beethoven Bot will probably answer something like this by default:

In reality, there is no reliable evidence that Beethoven met or auditioned for Mozart during his 1787 visit to Vienna.
Let's teach our bot this fact.
Navigate to Search » Faqs and click the (+) button at the top right of the worklist popup.

Enter the following info:
| Name: (Question) | Did Beethoven meet Mozart? |
| Answer: | It is certain that Beethoven visited Vienna in 1787. However, there is no reliable evidence that Beethoven and Mozart met during that trip. According to legend, Beethoven briefly auditioned for Mozart before returning home to be with his dying mother. |
| Topic: | Beethoven |
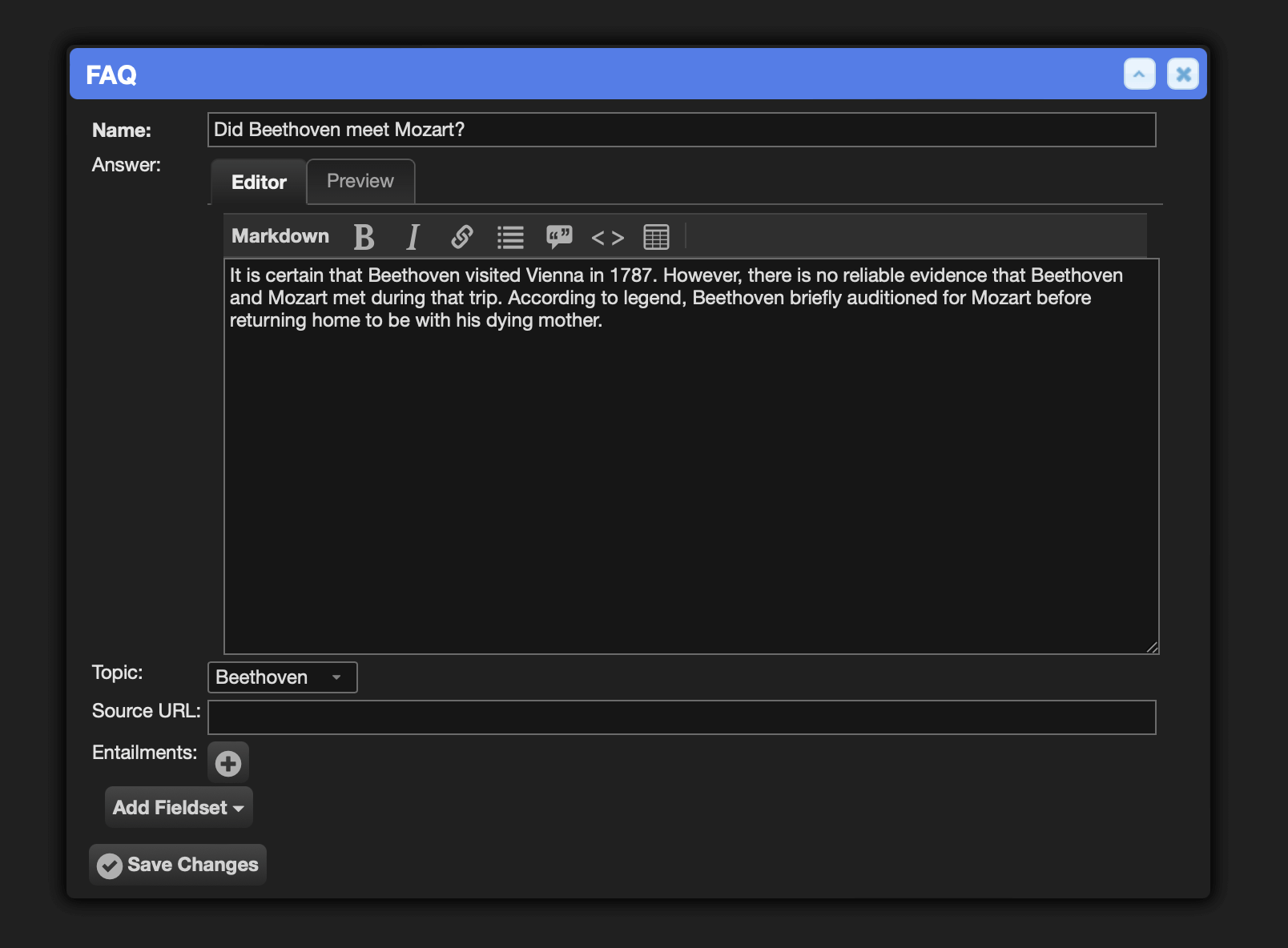
Click the Save Changes button.
Immediately after saving the FAQ entry, the text is embedded using OpenAI's API, and the resulting vector is stored on the Embeddings custom field on the record. The automation also invalidates the cache on the dataset.faq.embeddings.beethoven resource to rebuild the search index.
Let's ask again:
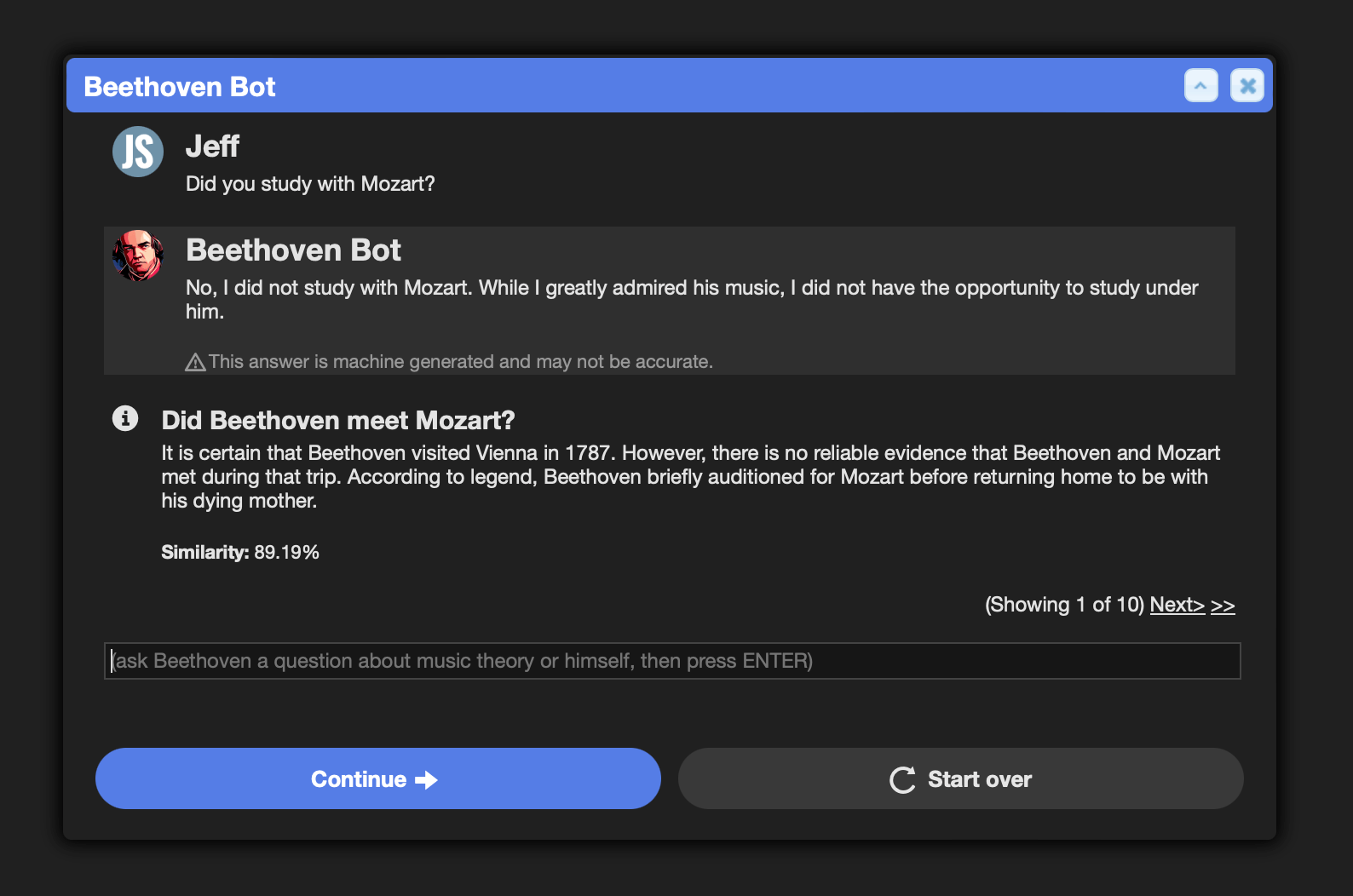
Add a new FAQ bot with your own topic
Now let's create a second bot for your own FAQ.
Add a new topic to the custom field
First, navigate to Search » Custom Fields and edit the Topic custom field on faq records to add a new topic.
Use the package to create your new bot
Then navigate to Setup » Packages » Import and paste the following package:
{
"package": {
"requires": {
"cerb_version": "10.4.3"
},
"configure": {
"placeholders": [],
"prompts": [
{
"type": "text",
"label": "Topic:",
"key": "prompt_topic",
"params": {
"default": "FAQ",
"placeholder": "(e.g. FAQ, Cerb, Beethoven)"
}
}
]
}
},
"records": [
{
"uid": "resource_faq_embeddings",
"_context": "resource",
"name": "dataset.faq.embeddings.{{{prompt_topic|permalink|lower}}}",
"description": "{{{prompt_topic}}} Bot FAQ embeddings",
"extension_id": "cerb.resource.dataset.jsonl",
"is_dynamic": 1,
"automation_kata": "automation/{{{random_string(8)}}}:\r\n uri: cerb:automation:dataset.faq.embeddings\r\n inputs:\r\n topic: {{{prompt_topic}}}"
},
{
"uid": "automation_faq_interaction",
"_context": "automation",
"name": "example.bot.{{{prompt_topic|permalink|lower}}}",
"extension_id": "cerb.trigger.interaction.worker",
"description": "Start a chat with {{{prompt_topic}}} Bot",
"script": "start:\r\n await:\r\n interaction:\r\n uri: cerb:automation:example.faqBot.interaction\r\n inputs:\r\n botName: {{{prompt_topic}}} Bot\r\n resourceUri: dataset.faq.embeddings.{{{prompt_topic|permalink|lower}}}\r\n imageUri: image.bot.{{{prompt_topic|permalink|lower}}}\r\n instructions: (ask {{{prompt_topic}}} Bot a question, then press ENTER)\r\n introduction: Hello {{worker_first_name}}! How can I help?\r\n chatGptPrompt@text:\r\n You are a support bot.\r\n You provide friendly, informative answers based ONLY on the Q&A below (don't make things up).\r\n",
"policy_kata": "commands:\r\n # [TODO] Specify a command policy here (use Ctrl+Space for autocompletion)\r\n "
},
{
"uid": "resource_image",
"_context": "resource",
"name": "image.bot.{{{prompt_topic|permalink|lower}}}",
"description": "A profile image for {{{prompt_topic}}} Bot",
"extension_id": "cerb.resource.image",
"automation_kata": "width@int: 100\r\nheight@int: 100\r\nmime_type: image/png",
"content": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAGQAAABkCAMAAABHPGVmAAAAtFBMVEWnqaunqay9vsA8PD4bGxtISEq4urwnJygyMjMuLi8GBgYgICGAgYQRERFKSkwVFRYMDAxMTE4qKiw4ODlBQUI1NTeUlplDQ0UkJCV6e358fYBFRUdxcnWBgoWgoqWQkpWKjI+jpaiEhYiZm56cnqKNj5JtbnFPT1F1dnlbXF5WVli0trlTU1ZZWVtfYGJRUVNhYmSHiItkZWewsrWsrrGpq66tr7GJio1naGprbG7////c3d6u9aGOAAAAAXRSTlOArV5bRgAABdVJREFUaN7t2umWmjAYBuCGxQUZFbVoMrKviopr1fb+76sJAgFkanBsT3/M+8cZ5fBMFr4knvkG/n6+fSFfSJYvpCGi23C/D3c6oHk1ovvTCc+Pv3cmIWVejKiBmCLdkaiCJlEdRsToixRpj9UGxGo8WuksiBuXkLbI3mPr9/FI2LIg834Z6e09k80xFIIMGRBXqSI9QRi8zYLg4juG/hoE1SNvQ0mSQBzAPzBqgvQYkD1Ggu2qFnH74kQMnQ+VPUF8BmSlLA3yV63vEcXACN9p7z9gfOgH/TlgQJS1RV5Op/09gm5IT6i901byHz6MluU6qmOtcTuOUYs76GKGLAFwTBwnR9p1xlsA/ohYOgZu0YiA0wJXiuQx4JIgb/r9eAxm+p8RNY974tL8sDOk1Dl6gpjVarcQBuaD2pU2Qz9wNFGOlAtLgoQVI+gJV/AAcVU8GhFXTpgiS3CP+GUjbvcU8AixTi3uLjBF1MocJ0hQMlajdsd5iACuJtYNgaCcBUE6gEZddkbtHXiMtOqUNUFCUIdIBUMcd0Y+YECiOmTX6fZ39xVKm8/jwKAFix93Yp0FOdQh0VarK4MeCTWm/HiqAhbkB1eXA6jEQYtOp0tGahZcyZ3NQMSIBpiQUy0SVdaLDS6aGYJL2kQ2lT5G9qwbiRqidTiWVrMNz2cIL/IYEYTJGiOBzoq0KkD0A5RjKxOK+PO5v+7g6iysRDwgrEhU7KXDCVQTvk8LyHVOsugNBm+BDJiRQ10TaHyxhIjzJH6AFxpRZ0Z+0CbURBbLSDuY37IR3oYbZuREh/k+hlhF2oF/Uy7CcBiyII9iLe+RGX/JFcl5AQL7NQheMNMeG0rB5xErrkeE7iJRepJkfhrR+h8ggjAK9tvNQJKWoBIdlze9CbL+GBmQvRLZ9uklAcX4c0FQZJ0VcRUGBAGa3RRfMEs+5k1GRGNBNoX60+nkyNsQsSFzFmRCjXEJGdpMyJ4FkVTjlrNYQQT9HnHorGiEhMlV7/iaCiL5FcSdxzz/vaOERUdhQswisiwiQhmxlemEIN0uL1NkxYRYBWTrupscwX4R8UUxQ9ozuWFL9HWO8OjMce6CrM5miMuBX0B2/SLS2+WIzX0UT8P5+fPEOZKJlhmylWWL7A2ThUl/LyJWXEa6eOWLA0FSGBGQ5MrzUyTLxm0BJIzeLSBIIZ2i5EjSF7gnNo+QX78sikCe38o4By5nEKLIGiNxGAZVxH+A4HgUsfl3RBCH4zJGN3LExePrIwg99CnE4fcyid3iKJMjhqLIECIPuqiKXO1btCRyEnRL+govGQIuSE7i5kh0okiAIDxHkYYsJUVWeDtimw7TFM4RU75ll/YV/l2lSAih02q1jnAXpogBkjRDNDmNe1J3yQ+alSEOggi0SBwIUwQ8gVi2XI0KUsQgXdW65QynCbJqhtDjS9nQrBTxIFRbWQ7omiDycwiwyowKUsTFw0FjwQW+xxQ0RSjjFRtCvyxAUUExoDjrqY2RWkYtLL+mXUAie96VwTMIjXvOGkIRoBkF5Yg08CxCmV3aEIpYyC0Ni/E0QuPYNqBIAkNQUFToNlsZdVAXq4IAFR0LyhllF1xZkBHrXtgrDX4+LDsWZMOKAE0tDj700iazIAYz4iJQelrSqRE+RhTAiJSfyeMZQuSmB61HiGA0QIDtpfXLgCReagcPEARYEfq0RI56RBAilX6j9SekZzc8mDp4HusaNDDiWcUmXrYbnEWSNc4SZ4UTr0P2czydx2dIYruAOY0RS8YC7am/gwAXQtpT1eim6TvpZYbxPAKMmp5yPC28LAOyT7+daqxVH298xcU2hJ7aHKnG9bfJ3pUsyQkikclkKgThx+S80xPasa9/BlFjUZyWEXJ0QkWEvPv+GWTdZ0Mk/3nEUFiR6fOIxoxI/zmi1iCIrGSv7C6wKSP0Oaki4SuncFpzd6+cwsANcf1NSm9Sd7dONu8u+fu4Fofgf/3Pgi/kC/lC/j3yG9v2DKXpBhIJAAAAAElFTkSuQmCC"
}
],
"events": [
{
"event": "record.changed",
"kata": "automation/{{{random_string(8)}}}:\n uri: cerb:automation:example.faqBot.recordChanged.embeddings\n disabled@bool:\n {{\n record__type is not record type ('faq')\n or record_topic != \"{{{prompt_topic}}}\"\n or (change_type == 'updated' and was_record_name == record_name)\n or change_type == 'deleted'\n }}\n inputs:\n faq@int: {{record_id}}\n resourceUri: dataset.faq.embeddings.{{{prompt_topic|permalink|lower}}}\n"
}
],
"toolbars": [
{
"toolbar": "global.menu",
"kata": "interaction/{{{random_string(8)}}}:\r\n label: {{{prompt_topic}}} Bot\r\n uri: cerb:automation:example.bot.{{{prompt_topic|permalink|lower}}}\r\n icon: chat\r\n"
}
]
}Enter the same topic you added to the custom field (e.g. Cerb) and click the Import button.
Chat with your bot
Click on the global menu in the bottom right and select your new bot from the list.
Customizing your FAQ bot
From Search » Automations edit the automation for your bot (e.g. example.bot.cerb).
In start:await:interaction:inputs: you can customize the bot name, image, introduction, instructions, and ChatGPT prompt.
Changing your bot image
To update the image of your bot, navigate to Search » Resources and edit it (e.g. image.bot.cerb). Upload a new image and click the Save Changes button.
Changing the global menu item
To edit the menu item for your bot, navigate to Search » Toolbars and edit global.menu.
Disabling text generation
If you wish to disable ChatGPT's text generation and only return the most similar FAQ entries, edit the example.faqBot.interaction automation and comment out the following two code blocks:
Around line 91:
# Have ChatGPT summarize an answer
#function/chatGpt:
# uri: cerb:automation:example.services.llm.chatGpt
# output: chatgpt
# inputs:
# temperature@float: 0
# prompt@key: chatGptPromptAround line 110:
#chatGpt:
# who@key: inputs:botName
# worker_id: 0
# icon_uri: cerb:resource:{{inputs.imageUri}}
# message: {{chatgpt.response.choices[0].message.content}}
# disclaimer: This answer is machine generated and may not be accurate.Scaling for large FAQs or busy bots
In this guide we use a Cerb resource record for simplicity. If you have a large FAQ (100+ Q&As) or high usage on your bot, you will have better performance by using a specialized vector database (e.g. Pinecone, Qdrant, Elasticsearch 8+, Redis Search) to store and compare your text embeddings.
These databases use strategies like Hierarchical Navigable Small Worlds (HNSW) to efficiently compare millions of vectors.
You would still use OpenAI's API (or a comparable method) to text embed your FAQ entries and each new user message.
Update the example.faqBot.recordChanged.embeddings automation to store embeddings in the vector database. Also store the FAQ record ID in the metadata.
In example.faqBot.interaction replace this block (around line 45) with a function that fetches results from the vector database:
# Fetch docs
function/docs:
uri: cerb:automation:example.faqBot.findSimilarDocs.resourceFile
output: matches
inputs:
query@key: promptQuery
limit: 10
resource_uri@key: inputs:resourceUriAs long as you return an object with this same structure you won't need to make other changes:
return:
response:
results:
0:
score: 0.99123123
data:
q: What is Cerb?
a: Cerb is a customer service and support platform that helps businesses manage their customer interactions.If your Q&A entries are fairly small (under 40KB for Pinecone) you can store the questions and answers in the vector database metadata. Otherwise just store the IDs, and load the FAQ entries in Cerb with record.search: in your function.